


考核方式

评分比例




2023 计算机前沿技术复现大赛 TOP 10 优秀作品展示
-
Submitted | GraphiMind: LLM-centric Interface for Information Graphics Design
(reproduced by Qirui Huang) -
S&P 2019 | Comprehensive Privacy Analysis of Deep Learning: Passive and Active White-box Inference Attacks against Centralized and Federated Learning
(reproduced by Huitong Jin) -
ICCV 2023 | UniFace: Unified Cross-Entropy Loss for Deep Face Recognition
(reproduced by Weijia Fan) -
TIP 2023 | Unmixing Guided Unsupervised Network for RGB Spectral Super-Resolution
(reproduced by Qi Ren) -
SIGMOD 2023 | QaaD (Query-as-a-Data): Scalable Execution of Massive Number of Small Queries in Spark
(reproduced by Jing Chang) -
SIGIR 2020 | LightGCN: Simplifying and Powering Graph Convolution Network for Recommendation
(reproduced by Yue Shen) -
UbiComp 2021 | RFaceID: Towards RFID-based Facial Recognition
(reproduced by Haiyi Yao) -
ISSTA 2021 | UAFSan: An Object-identifier-based Dynamic Approach for Detecting Use-After-Free Vulnerabilities
(reproduced by Yixuan Cao) -
AAAI 2023 | Weakly-Supervised Semantic Segmentation for Histopathology Images Based on Dataset Synthesis and Feature Consistency Constraint
(reproduced by Meidan Ding) -
TMI 2023 | Multi-Level Global Context Cross Consistency Model for Semi-Supervised Ultrasound Image Segmentation with Diffusion Model
(reproduced by Xiangwen Cai)
2023 计算机前沿技术复现大赛比赛回顾




2023 计算机前沿技术复现大赛入围作品简介
-

CVPR 2023 | Open-Vocabulary Semantic Segmentation with Mask-adapted CLIP
开放词汇语义分割的目的是根据文本描述将图像分割成可能在训练中没有看到的语义区域。最近的两阶段方法首先生成类不可知的掩码方案,然后利用预先训练好的视觉-语言模型,对掩码区域进行分类。作者通过挖掘现有的COCO-Captions数据集来收集构建蒙版图像-文本描述对,以此对CLIP微调,改善CLIP不能很好地对蒙版图像进行分类的情况。该方法对细粒度和多目标的分割效果不佳,为此,使用SAM更换原模型的mask生成器,使得该方法能够做出更高质量以及细粒度的分割。
-

SIGMOD 2023 | QaaD (Query-as-a-Data): Scalable Execution of Massive Number of Small Queries in Spark
Spark 是专为大规模数据处理而设计的计算引擎, 旨在通过对大数据集的同构操作实现高度并行来提高性能。但涉及I/O操作过多且计算量较小的小查询在实践中越来越占据主导地位,当前的Spark架构在处理小查询时无法达到最优速度。因此论文提出了QaaD,将小查询透明转换为具有大查询的工作负载,从根本上提高了Spark的执行速度, 实验证明QaaD比标准Spark提高了10.6倍到36.6倍。论文原实验环境复现相对困难,因此我将其整理为一套可执行的代码,一键操作完成实验环境的搭建和部署。
-
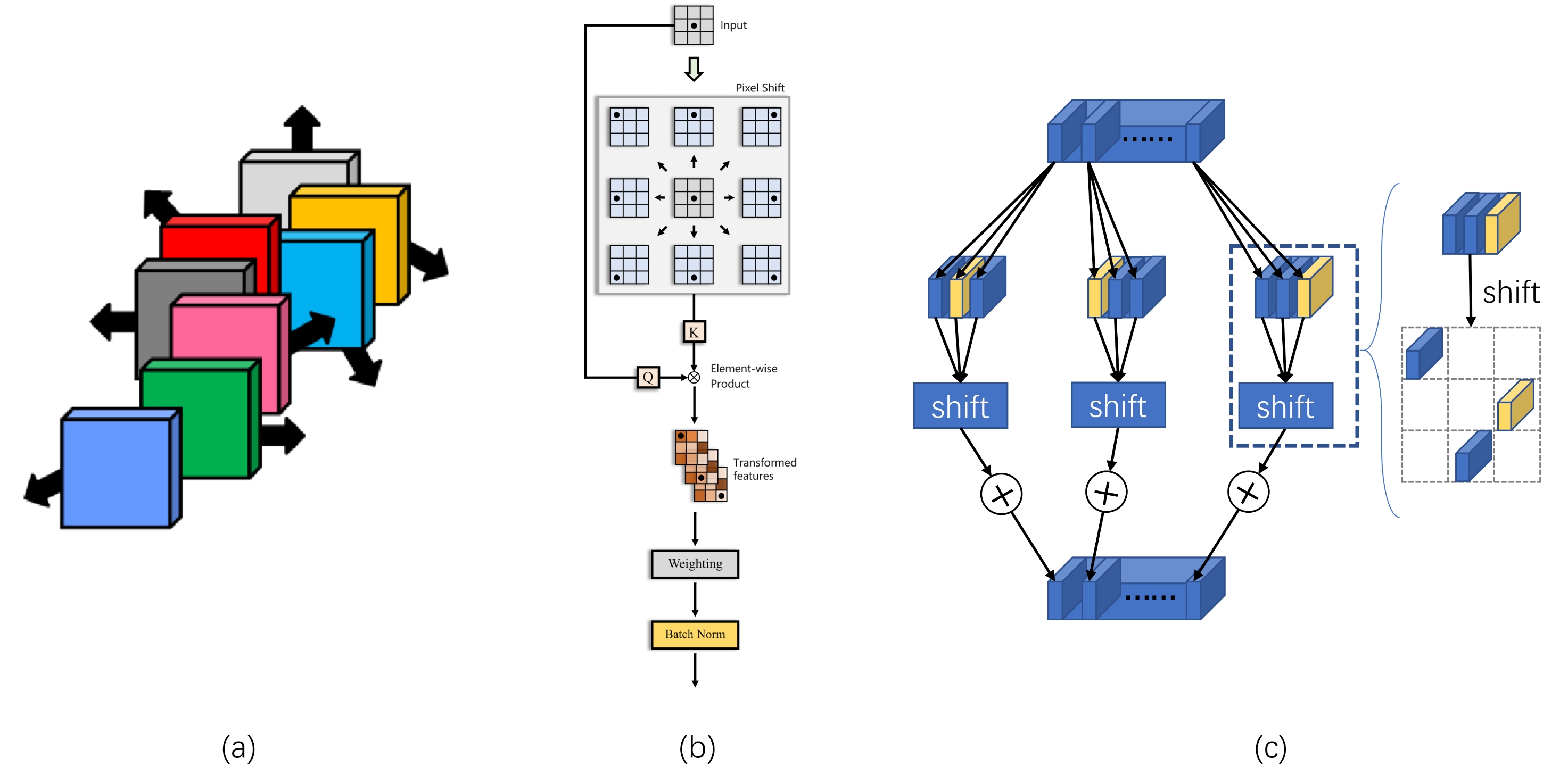
ICLR 2023 | More Convnets in the 2020s: Scaling up Kernels Beyond 51x51 Using Sparsity
大卷积核经由ConvNeXts重新引入并将基础CNN推高到新的baseline之后,一系列工作沿着将卷积核的尺寸增加的方向继续推高此基准,其中在Sparse Large Kernel Network (SLaK)中卷积核的尺寸达到了51*51。然而,如SLaK中所用到的大卷积核、稀疏权重矩阵都不是硬件友好算子。因此继续增加卷积核的尺寸的方式并不是一个特别好的选择,而且这种方式会受到特征尺寸天花板的限制。而另一方面,大卷积核重新被引入的始作俑者transformer所具备的稀疏注意力特性也没能在大卷积核中有所体现。基于此,我们提出了shift-wise的算子:使用普通小卷积核和平移操作可达到此类大卷积核的效果并且可以实现远距离的稀疏依赖特征。所提出的shift-wise不仅是软硬件友好的,而且使得CNN在稀疏注意力方面有了更好的体现。在稀疏依赖这一新的角度将普通CNN的baseline继续推高,并大幅降低计算量。在分类数据集imagenet-1k上,我们提出的shift-wise在精度上超越了STATE-of-ART的SLaK方法,而且还有进一步提升的空间。综上,我们对SLaK的改进算子shift-wise可以将更基础的CNN提升到新的基准,同时为CNN的基础结构贡献了新的成员。
-

CCIR 2022 | ID-Agnostic User Behavior Pre-training for Sequential Recommendation
经典的序列推荐算法基于物品 ID 编码物品,通过建模不同的神经网络架构建模用户行为,以捕捉潜在的用户兴趣。本报告复现的 IDA-SR 模型提出了一种与物品 ID 无关的用户行为预训练序列推荐方法。该方法抛弃了基于 ID 编码的物品表示,采用预训练语言模型作为文本编码器从丰富的文本信息中学习物品表示,设计一个端到端的预训练网络建模用户偏好,并在下游任务上微调以提高推荐性能。本报告根据其论文细节复现模型,其复现结果在三个公开数据集接近原始论文报告的结果。本复现报告证明,IDA-SR 模型在下游数据集微调时能够接近基于物品 ID 编码的模型,但性能依然严重依赖基于物品 ID 表示的微调;同时通过消融实验证明,该模型提出的置换物品预测预训练任务表现不稳定。报告研究发现,影响模型性能的瓶颈是底层的文本编码表示和语义空间适配层,因此提出了一种基于局部敏感哈希的语义映射网络。该网络可以弥补预训练模型空间和推荐空间的语义差距,有效地提高基于文本的语义表示迁移至推荐场景的能力。
-

ICCV 2023 | Segment Anything
SAM构建了迄今为止最大规模的自然图像数据集SA-1B,并在计算机视觉的不同子领域有着极强的零样本泛化能力。作为主要用于自然图像分割的视觉大模型,SAM在医学图像上表现并不如意。基于医学图像存在低对比度、大量噪声、不规则的掩码形状等问题,将SAM直接应用于医学图像领域将得到灾难性的分割结果。而SAM强大的预训练权重又可以为医学图像分割带来更强的泛化能力,因此,我在已有的对SAM模型的改进的CNN模块基础上添加多头聚合器,使SAM模型更加关注局部信息,从而大大提高SAM模型在医学图像分割领域的性能。
-

ACM ICN 2023 | PCLive: Bringing Named Data Networking to Internet Livestreaming
NDN数据命名网络自被提出后就成为国内外的研究热点,其将内容本身,而非地址,看作网络的主要内容,并以此目标颠覆了当前基于主机的网络架构。因而,NDN成为下一代互联网中一个具有代表性的网络架构。然而,正是因其颠覆现有TCP/IP架构,缺乏应用的支持是当前NDN网络发展的最大障碍。本项目复现的论文主要内容是在现有网络架构下抽象出NDN逻辑网络,将应用程序需要传输的数据包NDN化,并通过该NDN逻辑网络进行内容分发,以最大兼容现有的网络体系结构并发挥NDN网络优势。基于该网络设计方案,开发出PCLive直播系统,将互联网直播通过NDN架构转发,通过在真实场景应用此系统,观察直播实时播放效果,验证该设计的有效性。同时,原文作者仅在已知数据存在的前提下实现了分发,并未关注数据发现环节。因此,我在原文已实现的数据分发功能基础上进行改进,使系统各节点具备网络资源发现能力,使其提出的数据分发架构对不同的应用场景有更高的兼容性。
-

Environmental Pollution 2021 | Deep Learning Based Regression for Optically Inactive Inland Water Quality Parameter Estimation Using Airborne Hyperspectral Imagery
本项目复现了论文提出的PixDNNR和PatchDNNR两种深度卷积回归网络,通过比较基于像素(pixel)和块(patch)两种输入尺度在高光谱图像处理方面的表现差异,深入研究了其性能特点。针对真实场景高光谱图像水质分析及空间展示的应用需求,对原论文中的PatchDNNR模型进行了重新设计和改进,将ConvNext网络作为主干网络结构迁移到模型中,同时在深度回归网络中引入了即插即用的SEBlock和ACmix模块,用于挖掘高光谱图像的深度特征,从而有效地捕获水质参数的重要特征,使得该算法提高水质分析的准确性和可靠性。
-

AAAI 2023 | GraphSR: A Data Augmentation Algorithm for Imbalanced Node Classification
现有的GNN自然倾向于具有更多标记数据的多数类别,而忽略那些具有相对较少标记数据的少数类别。在论文中,作者寻求从图的大量未标记节点中自动增加少数类。具体来说,GraphSR基于相似性的选择模块和强化学习(RL)选择模块,以增加具有显著多样性的未标记节点的少数类。实验表明,GraphSR在各种类别不平衡数据集上优于最先进的基线。同时,在复现过程中发现,优先将节点的一阶邻居加入训练集,可以达到与论文中使用强化学习相同的实验效果,有效降低了算法时间复杂度。
-

SIGIR 2020 | LightGCN: Simplifying and Powering Graph Convolution Network for Recommendation
图卷积网络(GCN)在推荐系统中备受关注,其中LightGCN因其简单高效而脱颖而出。研究表明GCN的非线性激活和特征变换对预测结果不利。因此,LightGCN通过在线性传播用户和项目嵌入的方式学习特征,并使用加权和生成最终嵌入。这种简单线性的模型易于实现和训练,但在复现中存在过拟合问题。为解决此问题,我改进了优化函数,引入了随机负采样作为辅助损失。在原数据集上验证,NegLightGCN表现更好,有效降低了过拟合。
-

ACL 2022 | GLM: General Language Model Pretraining with Autoregressive Blank Infilling
现有各种类型的预训练架构都无法对自然语言理解、无条件生成和有条件生成中的所有任务都表现最佳。本文提出了一种基于自回归空白填充的通用语言模型(GML),该模型通过添加2D位置编码并允许任意顺序预测跨度来改进空白填充预训练,同时通过变化掩码数量和长度,来针对不同类型的任务进行预训练,展示了出色的性能以及对不同下游任务的通用性。基于GLM强大的自然语言处理能力,将其应用于Ai生成新闻检测下游任务中,通过GLM对CNN/Daily Mail数据集中的highlight进行扩写,生成训练集和测试集。在进行AI生成新闻检测时,爬取CNN网站中相关新闻作为事实依据,与待检测新闻通过获取GLM的embedding表示并进行bert-whitening优化开展相似度分析,同时使用GLM进行情绪分析,将所获信息与待检测新闻共同作为GLM输入进行AI生成新闻检测。
-

SIGIR 2020 | LightGCN: Simplifying and Powering Graph Convolution Network for Recommendation
在基于图卷积神经网络(GCN)设计的用于推荐系统的模型中,直接继承了GCN中的大部分操作,但由于推荐系统数据的稀疏性,这些操作并不一定是有效的。本文首先对当时性能最优的NGCF进行消融分析,根据其结果重新设计了GCN,提出了更适合推荐系统的LightGCN,达到了很好的效果。本篇复现工作基于GCN层数过深会导致过平滑的特点在进行信息聚合前加入了一层简化的Transformer,经过实验发现与原复现结果相比提高了模型性能。
-

EMNLP 2017 | DeepPath: A Reinforcement Learning Method for Knowledge Graph Reasoning
在过去的知识图谱推理方法中,Path-Ranking Algorithm (PRA) 在完全离散的空间中操作,这导致在知识图谱中评估和比较相似实体和关系变得困难。为了克服这些局限性,本文作为首篇将强化学习应用于知识图谱推理领域的论文,提出了基于蒙特卡洛的DeepPath方法,通过在知识图谱向量空间中进行推理,设计并使用策略梯度训练和新颖的奖励函数来引导代理学习关系路径。本篇复现工作尝试采用Actor-Critic、agent-only的PPO-clip方法替换原论文中的蒙特卡洛强化学习方法,并增加实验的并行批处理和可视化操作,比复现的结果提高了训练效率和性能。
-

TMI 2023 | Unsupervised Medical Image Translation with Adversarial Diffusion Models
SynDiff是一种基于对抗扩散建模的新方法,用于提高医学图像翻译的性能。它通过条件扩散过程,逐步将噪声和源图像映射到目标图像上,捕获图像分布的直接相关性。在反向扩散过程中,采用对抗投影模块实现加大步长扩散,提高推理效率。同时,作者设计了一个循环一致架构,使网络可以在不配对的数据集上进行训练,结合扩散和非扩散模块,提高效率的同时保证生成图像的保真度。在多对比MRI和MRI-CT翻译任务中,SynDiff与GAN和其他扩散模型相比有显著优势。

-
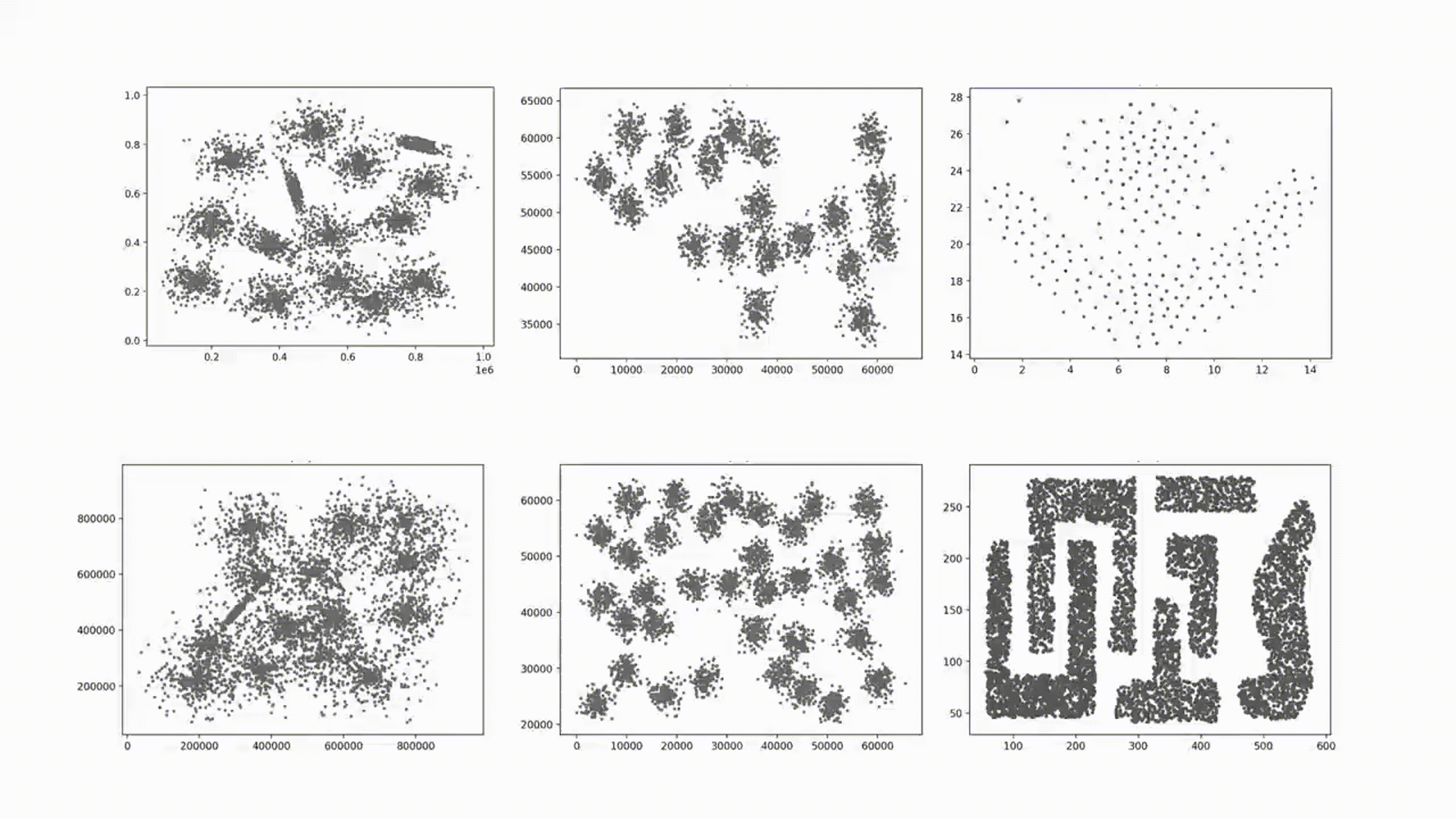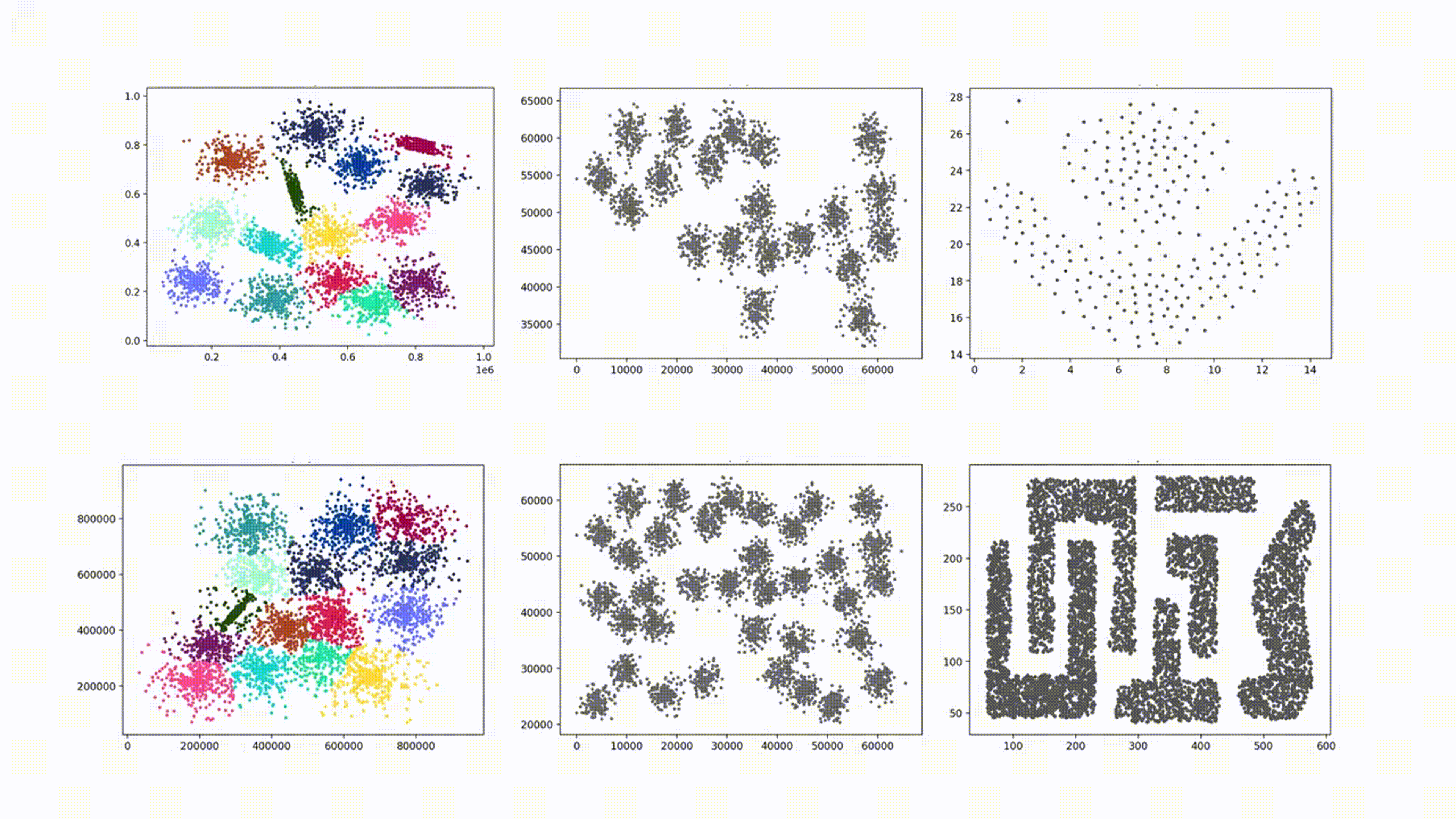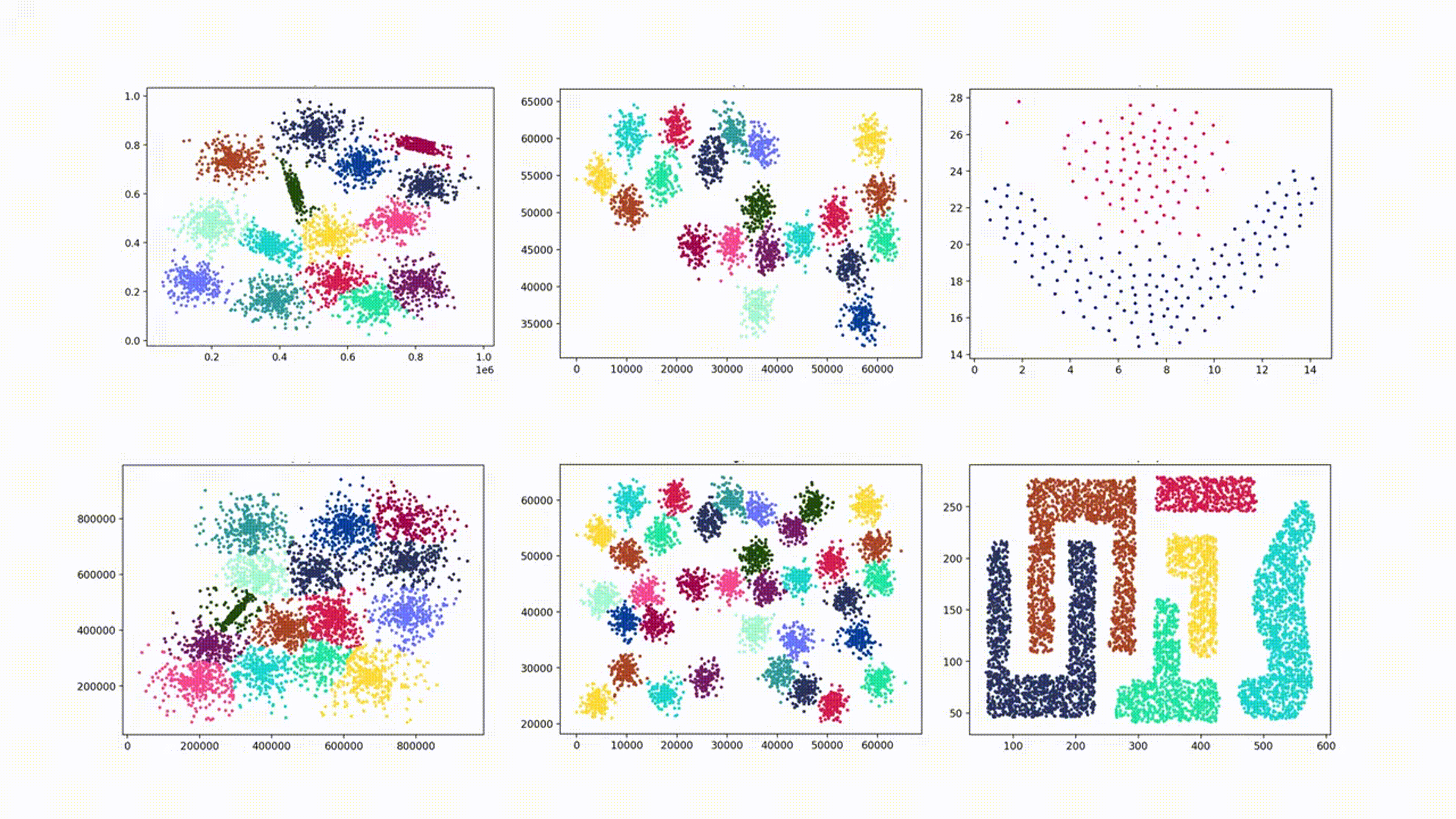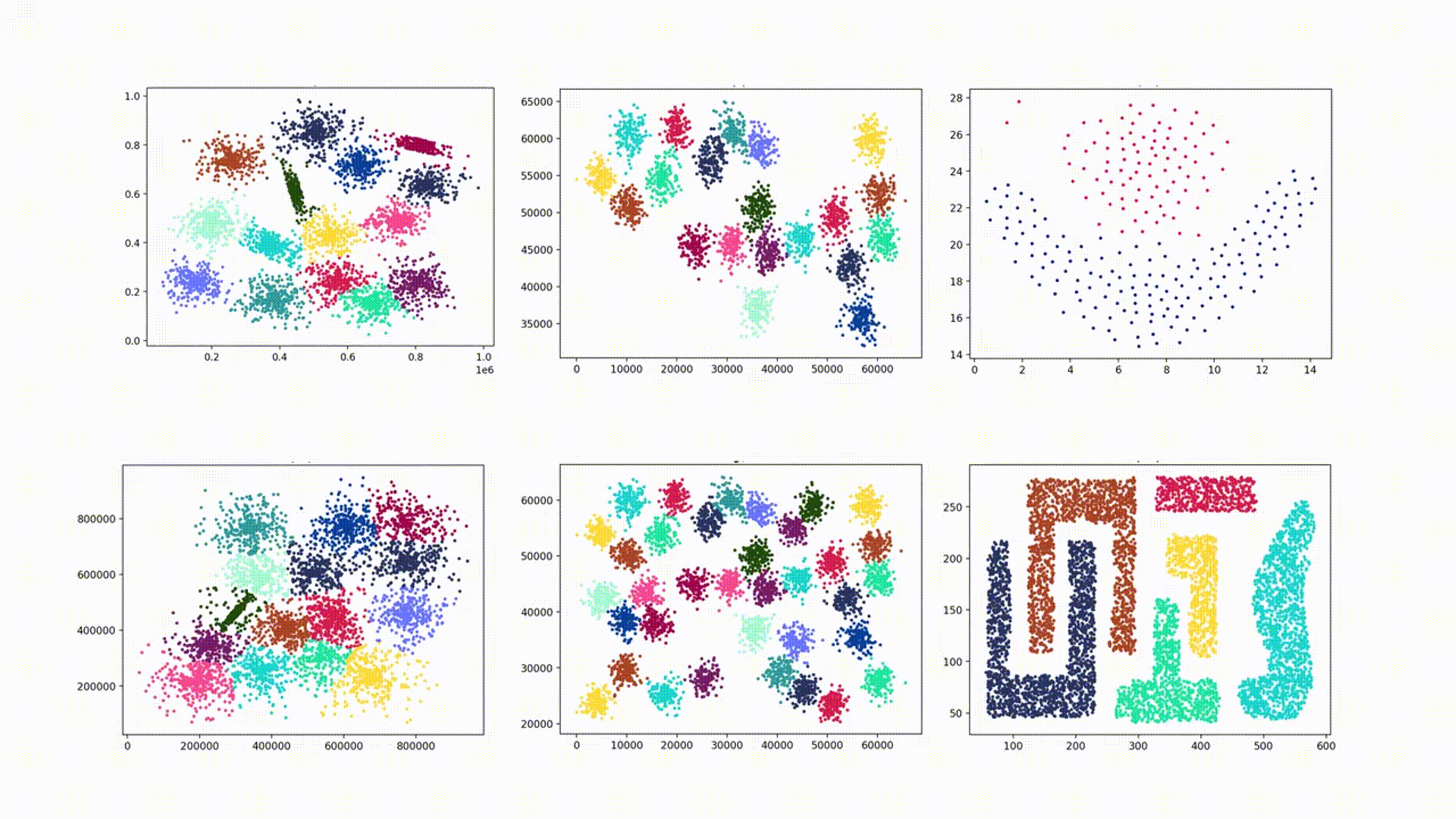
INS 2023 | A Novel Open–set Clustering Algorithm
DOS(Delta Open Set)算法能够识别复杂形状的簇,但是其对输入参数的依赖性大,且由于其通过特定函数生成规则邻域用于识别开集,导致DOS在处理重叠的集群和高斯集群时表现较差。本项目复现的DOS–IN(Irregular Neighborhoods)算法基于对象之间的相似性生成不规则邻域,能够自适应对象的分布,不仅可以准确地区分重叠的簇,而且具有更少的输入参数。此外,DOS-IN引入了小簇合并机制,解决DOS在识别高斯簇方面的不足。但DOS–IN算法在数据预处理与小簇合并机制上仍存在优化空间,因此,本项目在程序中加入了数据预处理并改进了小簇合并机制,从而提高该算法的准确率。
-

CVPR 2022 | AUV-Net: Learning Aligned UV Maps for Texture Transfer and Synthesis
现有的三维模型UV映射算法不会考虑模型之间的语义一致性,往往会将不同模型的同一语义部件映射到UV空间中的不同区域,使得纹理生成非常困难。本文作者以特征脸技术为启发,通过简单的点云重建任务,为同一个类别中的不同三维模型重新学得了语义一致的UV映射,大大降低了纹理迁移和生成的难度。由于方法一直未开源,故本项目从头复现了文章中提出的算法,包括数据处理、网络实现、损失计算等,复现完成后,在纹理迁移任务上进行了验证,结果基本达到原文水平,并进一步对复现过程中发现的问题提出了新的解决方案。
-

ICLR 2023|A Time Series is Worth 64 Words: Long-term Forecasting with Transformers
本文提出了一种基于 Transformer 模型的有效设计,以用于多元时间序列预测,名为PatchTST。该模型的关键改进点主要为(i)将时间序列分割为子序列级别的patch,作为 Transformer 的输入; (ii) 通道独立性,其中每个通道包含单个单变量时间序列,该序列在所有序列中共享相同的嵌入和 Transformer 权重。其中patch的设计不仅保留了局部语义信息,减少了内存使用量,还使模型在更长的时间序列预测上得到了较好的效果。与基于Transformer 的SOTA模型相比,本文提出的PatchTST模型可以显著提高长期预测精度,考虑到不同时间序列的振幅不同,我在尝试了不同的patch输入之后,选择其中较好的几个patch,使用多头patch的通道作为输入,进一步提高了模型的预测精度。
-

AAAI 2023 | Weakly-Supervised Semantic Segmentation for Histopathology Images Based on Dataset Synthesis and Feature Consistency Constraint
组织分割是计算病理学中的一项关键任务,因为它具有指示癌症患者预后的理想能力。目前,许多研究尝试使用图像级标签来实现像素级分割,以减少对精细注释的需求。 为了解决类激活图分割边界不准确的问题,本文提出了一种名为 PistoSeg 的新型弱监督组织分割框架,该框架通过将组织类别标签转移到像素级掩模来以完全监督的方式实现。但是该方法在构建像素级数据集时,放大了病理图像的同质性,从而影响分割效果。为此,我引入clip作为特征提取器,借助文本与图像的匹配,得到前景区域,抑制背景区域,通过该方法得到更完整的CAM图。
-

VLDB 2024 | Text-to-SQL Empowered by Large Language Models: A Benchmark Evaluation
在text-to-sql领域内,使用大语言模型Large language models (LLMs)已成为一种新的趋势,但是现在在该领域内依然缺乏系统性的基准,而阻碍了设计有效、高效和经济的text-to-sql任务解决方法,本文中从问题表示、示例选择、示例组成三个方法探究了prompt在text-to-sql领域的应用,并提出了DAIL-SQL在Spider数据集取得很好结果。我在DAIL-SQL的基础上,提出了信息量更为丰富的OPENSQL问题表示方法,在SPIDER数据集和BIRD数据集都在DAIL-SQL基础上得到了提升。
-
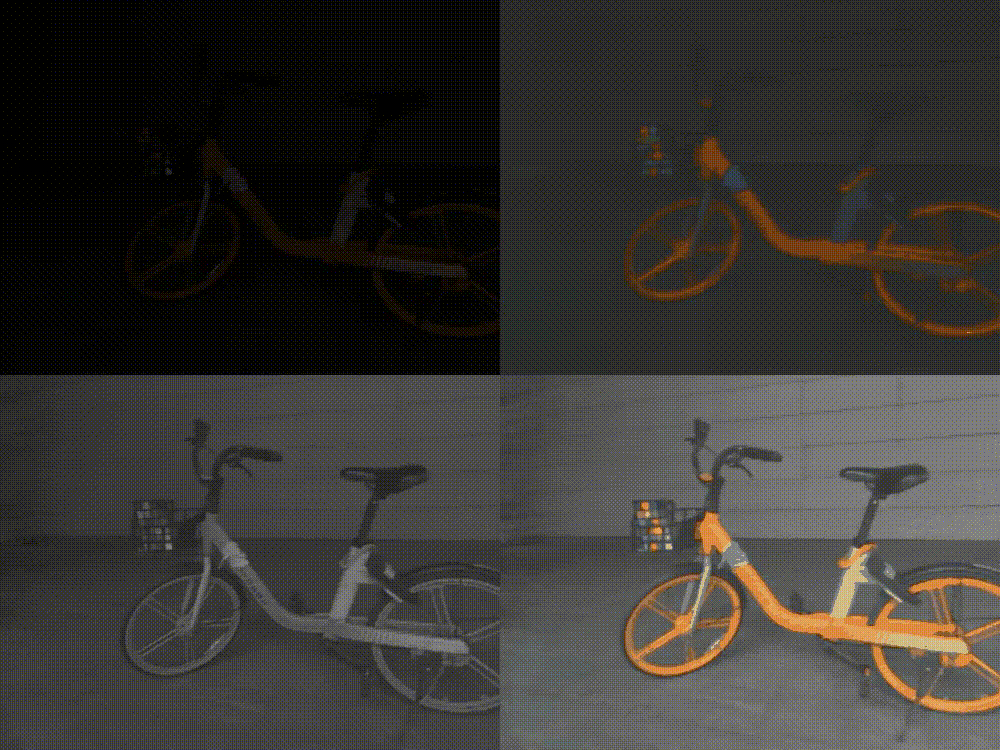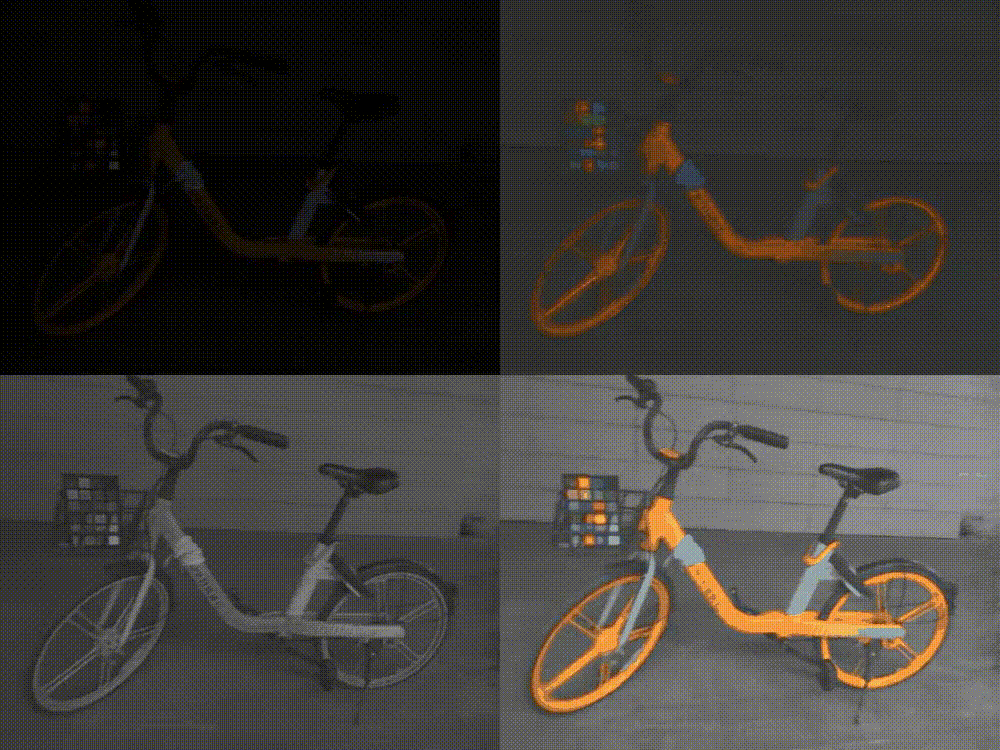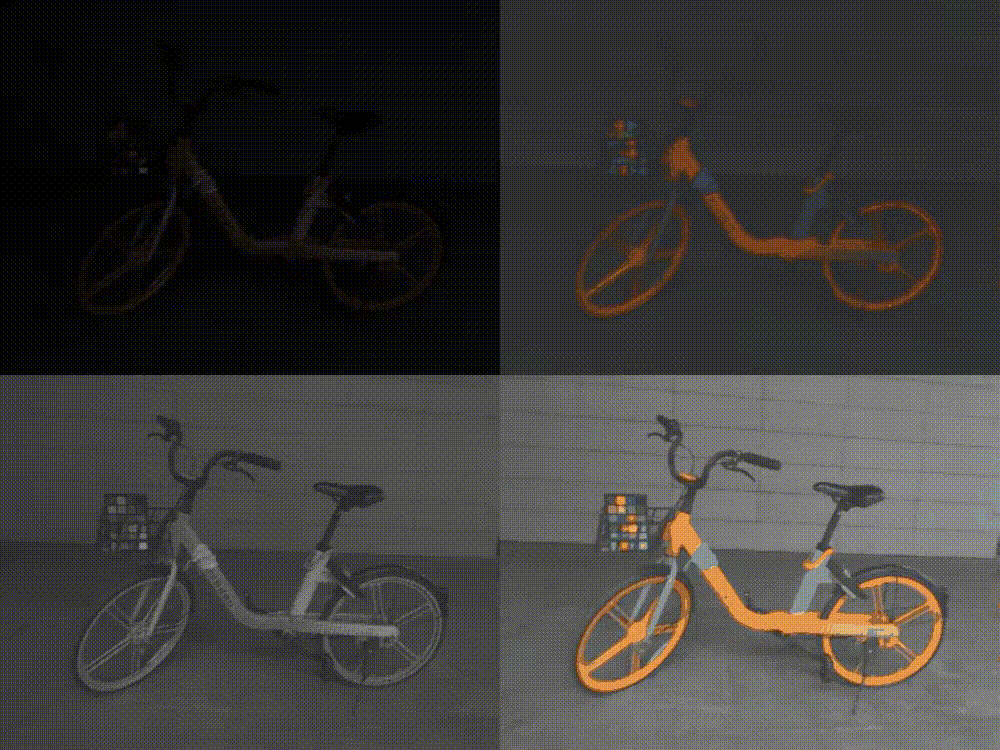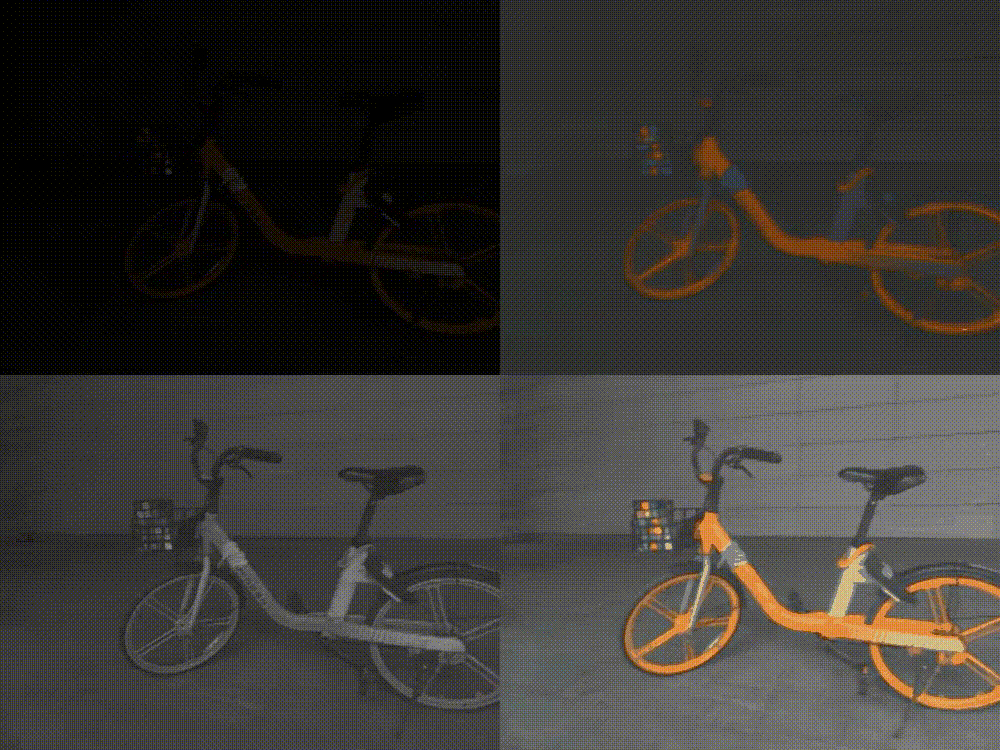
ICCV 2023 | Lighting up NeRF via Unsupervised Decomposition and Enhancement
给定场景的一组图像和相应的相机姿势,神经辐射场(NeRF)是一种有效且有前景的新视角合成方法。本文作者面向新视角合成的低光增强任务,受到二维图像增强方法中的Retinex理论的启发,实现了以无监督的方式直接从sRGB低光图像合成正常光的新视图。在复现过程中,为了增加细节以及平滑噪声,我对其优化策略进行修改,引入了一种即插即用的随机结构性损失,考虑全局信息。而因为原始数据集无正常光图像无法定量分析,因此我还在另一具有多视角低光/正常光图像对的数据集进行实验,在一定程度上比原文取得了更好的结果。
-

CHI 2021 | ElectroRing: Subtle Pinch and Touch Detection with a Ring
生物阻抗技术通过传送微弱电流至身体组织,以测量和分析电流在人体中传播的阻抗,广泛应用于医疗保健领域。本项目复现的ElectroRing方法将此技术用于人机交互指环,利用单点主动电感应传感方法检测指尖与皮肤接触,以可靠捕捉用户细微的手指捏放操作。在复现工作中,我参考论文内容,自行设计了指环硬件结构和上位机程序,并将生物阻抗与IMU运动姿态追踪相结合,开发了三个演示应用,最后,结合VR设备,进一步探索了指环在虚拟现实交互场景中的应用。
-

CVPR 2020 | Multi-Task Collaborative Network for Joint Referring Expression Comprehension and Segmentation
指称表达理解和指称表达分割任务均涉及到自然语言处理和计算机视觉两个领域,是两个不同但存在联系的跨领域任务。本项目复现的Multi-Task Collaborative Network (MCN) 首次提出将指称表达理解和指称表达分割结合联系起来,在一个统一的网络中进行协同学习,使指称表达理解能够帮助指称表达分割更加准确地定位目标物体,使指称表达分割帮助指称表达理解更好地进行文本图像配准。在此基础上,本项目参考已有相关任务算法,在图像编码器、多模态特征融合模块、数据增强等方面对MCN做出改进,进一步提升模型性能。
-

ECCV 2020 | Thinking in Frequency: Face Forgery Detection by Mining Frequency-aware Clues
从传统内容真伪取证,到DeepFake取证,再到大模型AIGC取证,新的问题越来越多。原文从频域的角度分析真假图片的差别,提出FAD(Frequency Aware Decomposition)和LFS(Local Frequency Statistics)两种方法来挖掘图片的特征。改进的方法中,认为更加应该关注图片的高频部分(AIGC模型难以生成的部分),从中寻找AIGC生成模型的破绽。此外还从振幅,相位的角度进行挖掘,寻求real图片和fake图片的本质差异。
-
SIGKDD 2023 | Generalizable Low-resource Activity Recognition with Diverse and Discriminative Representation Learning
数据资源的匮乏以及不同用户的差异带来的数据分布偏移是人类活动识别(Human Activity Recognition, HAR)中不可避免的两大挑战。要实现具有良好泛化能力的HAR迁移模型,不仅需要足够的数据(多样性),还需要构建能够提取域不变特征的神经网络(可辨别性)。复现的论文使用域泛化的思想设计了HAR的迁移模型,在增加数据多样性的同时保证的数据的可辨别性。在此基础上,我扩展了新的数据集,并丰富了原文的实验设计。
-
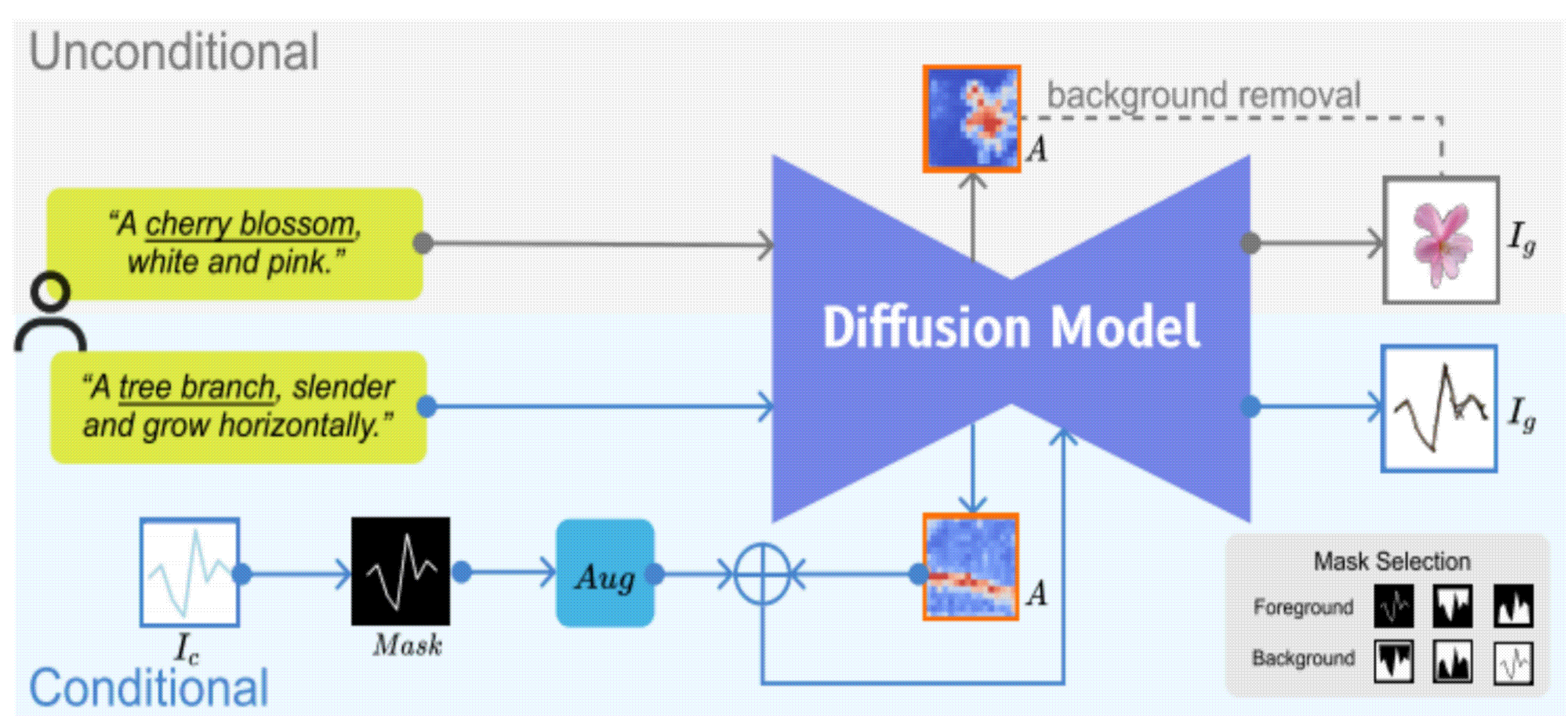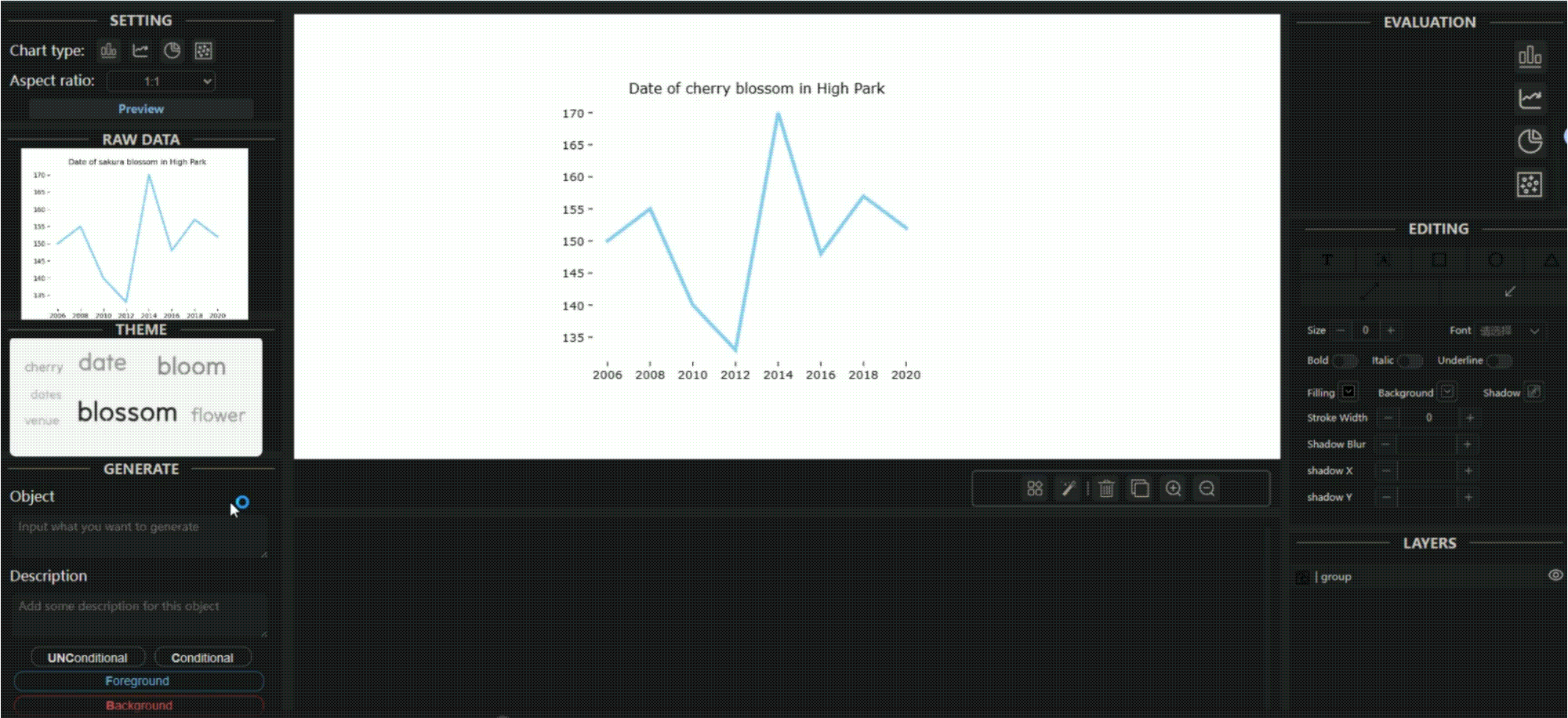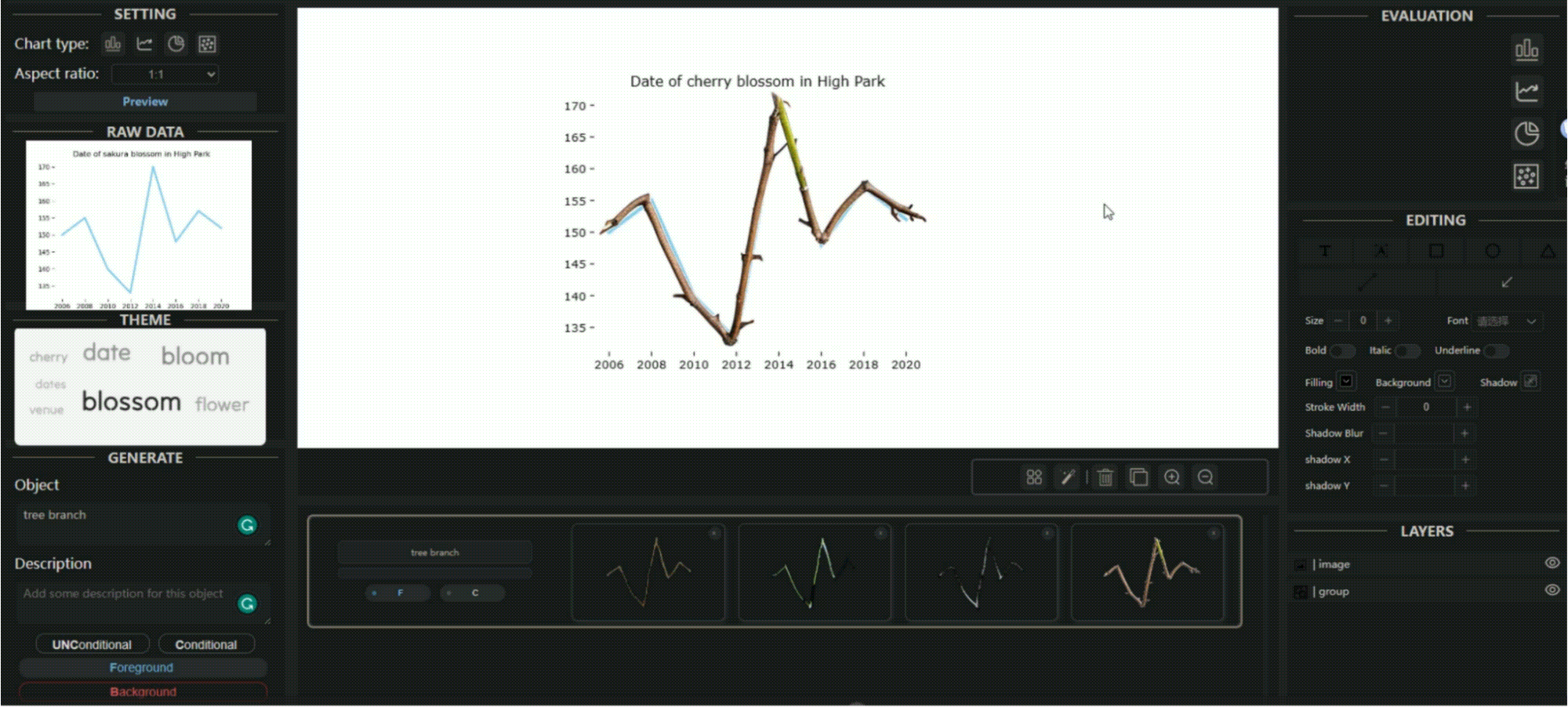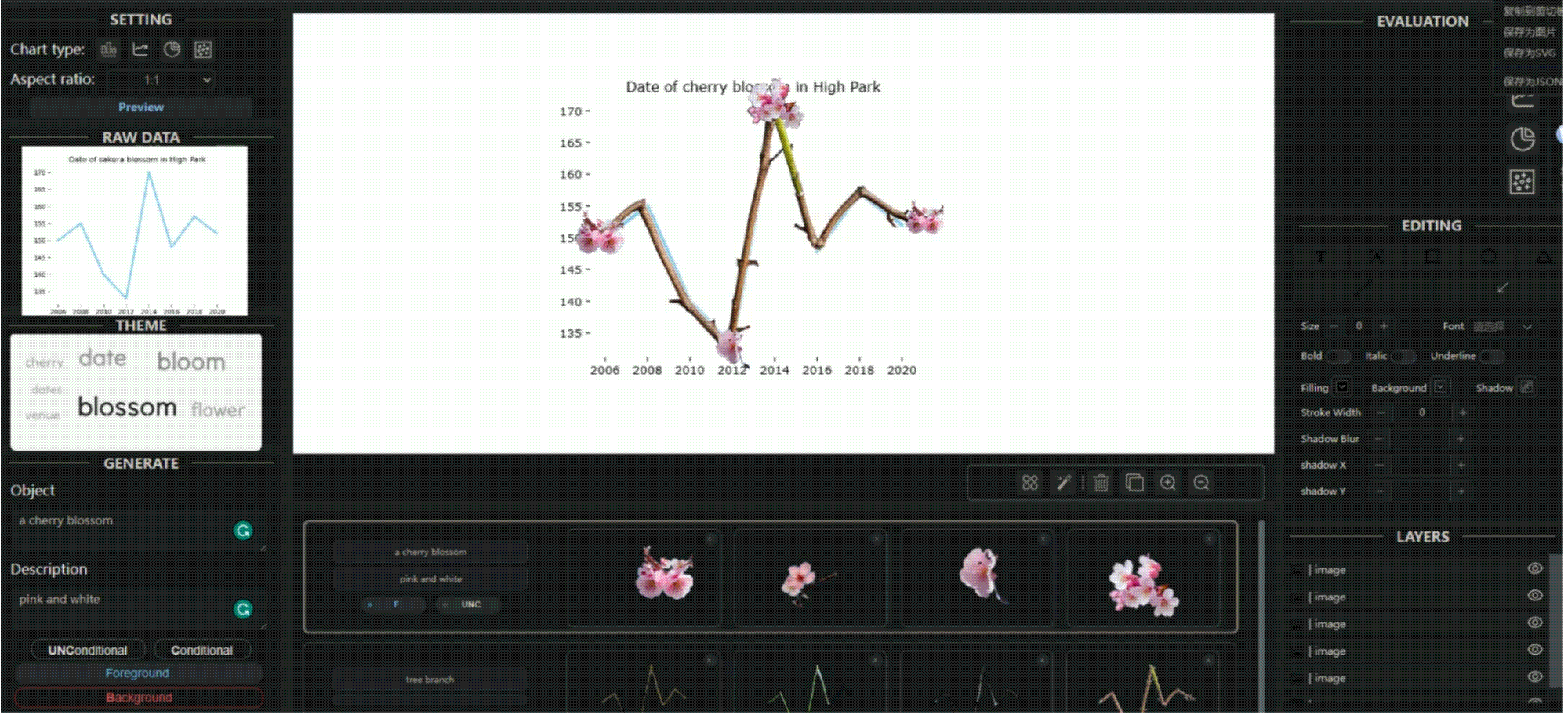
TVCG 2023 | Let the Chart Spark: Embedding Semantic Context into Chart with Text-to-Image Generative Model
图形可视化将数据与语义上下文融合在视觉表示中从而传递复杂信息,但主流方法通常依赖于专用语料库,可能影响数据完整性。本文介绍了 ChartSpark ,一个基于文本输入中传达的语义上下文和嵌入在简单图表中的数据信息的图形可视化的系统。实验还开发了交互式界面,包括文本分析、编辑和评估模块,用户可生成、修改和评估图形可视化。在此基础上,我扩展了生成有条件前景图片的方法,能够更加精准可控地让生成的图片边缘形状与数据表中的折线,饼图等边缘形状拟合。
-

S&P 2019 | Comprehensive Privacy Analysis of Deep Learning: Passive and Active White-box Inference Attacks against Centralized and Federated Learning
深度神经网络容易受到各种推理攻击,因为它们会记住有关其训练数据的信息。该文章利用随机梯度下降算法的隐私漏洞,设计白盒推理攻击来对深度学习模型进行全面的隐私分析。本工作首先复现原文的实验结果,然后探究了深度网络的不同层泄漏隐私的差异,以及在不同模型下各层隐私泄漏的区别。在CIFAR100数据集上的广泛实验结果表明,不同模型的不同层所泄漏的隐私有所区别,既取决于参数量的多少也取决于层的位置。
-

CVPR 2023 | Re-thinking Model Inversion Attacks Against Deep Neural Networks
深度神经网络(Deep Neural Networks,DNNs)已被广泛应用于涉及私人和敏感数据集的诸多领域,如人脸识别、医疗保健等,但DNNs易遭受各类获取机密数据集知识的隐私攻击,特别是模型反演攻击(Model Inversion Attack,MIA)。本工作通过分析现有最先进的白盒MIA(GMI和KEDMI)中存在的问题(次优的身份损失设计和MI过拟合),并提出相应的改进方案(更优的身份损失设计和模型增强),最后通过充分地实验验证改进方案的有效性。在本次复现过程中,我发现原论文中基于知识蒸馏所得到的增强模型的预测精度较低,故通过改进知识蒸馏过程所使用的损失函数,提高了增强模型4%~12%的预测精度,进而提高了2%~5%的反演攻击精度。
-

ISSTA 2021 | UAFSan: An Object-identifier-based Dynamic Approach for Detecting Use-After-Free Vulnerabilities
释放后使用(use after free,UAF)漏洞严重危害软件安全。相比起其他内存漏洞,UAF漏洞更难通过人工排查或静态分析发现。基于证据的动态检测工具一般只记录指针或对象的合法性,但是悬空指针指向的内存被再次分配后,现有工具出现不同程度的漏报。为了解决这一问题,UAFSan设计了显式锁钥方案,使用唯一标识符单独标识堆对象,可以在内存检查时通过指针和堆对象的标识符的一致性判断再分配是否发生。我发现并修正了动态UAF检测工具UAFSan的源代码的2个错误,并发现它存在漏报使用标准C库函数realloc()的C/C++程序的UAF漏洞的情况,我给出2种改进方案:1)改进重分配管理算法;2)改进内存访问检查算法。实验结果证明基于改进方案实现的UAFSan提高了检测UAF漏洞的准确性,且产生的时间和内存开销可以忽略。
-

ACHA 2022 | A Tailor-made 3-dimensional Directional Haar Semi-tight Framelet for pMRI Reconstruction
并行磁共振成像(pMRI)技术通过同时采集多个线圈的部分k-空间数据,借助重建算法填充缺失数据,实现对磁共振成像过程的有效加速。由于pMRI重建是一个病态逆问题,因此需要运用正则化技术对解进行适当约束。本项目复现的l1-W3D重建算法以SPIRiT模型为基础,结合三维紧框架正则化技术,通过挖掘不同线圈数据之间的相关性,得到高质量的重建图像。在复现的过程中,我采用PD3O算法求解l1-W3D模型,取得了良好的实验结果,改进后的算法执行时间相比原文算法减少了约20%。
-

ICLR 2023 | Ordered GNN: Ordering Message Passing to Deal with Heterophily and Over-smoothing
大多数图神经网络遵循消息传递机制。然而,当对图应用多次消息传递时,它会面临过度平滑的问题,导致节点表示难以区分,并阻止模型有效地学习较远节点之间的依赖关系。另一方面,具有不同标签的相邻节点的特征很可能被错误地混合,导致异质性问题。文章提出对传递到节点表示的消息进行排序,其中特定的神经元块针对特定跃点内的消息传递。并使其可以在同质和异质数据集的设置中同时实现最先进的效果。本工作主要包含根据描述复现文章效果,并扩展了实验所使用的数据集,在多个数据集上验证了模型的性能,进一步验证模型性能。
-

FAST 2020 | Scalable Parallel Flash Firmware for Many-core Architectures
传统的FTL设计将所有的任务都放在一个大的软件栈中,尽管多核处理器已经广泛应用于SSD控制器,由于软件栈的深度耦合,其采用的I/O请求与处理线程一对一映射的线程模型无法将多核处理器的计算能力完全发挥,进而限制了其存储性能。原文的DeepFlash架构通过将FTL分为三个主要阶段,基于多对多的线程模型,以pipeline的方式并行执行,以达到可以处理大量I/O请求的目的。但原文中的三个阶段之间依赖性强,无法很好地体现pipeline的并行性。于是本项目基于这点不足进行了改进,最大程度减小阶段间的依赖,基于多对多线程模型,实现无锁无环的PipeSSD架构,并在仿真平台和硬件平台上验证了该设计的有效性。

-

AAAI 2023 | Multi-Modality Deep Network for Extreme Learned Image Compression
现存的图像压缩算法仅利用原始图像这单一模态信息和其他辅助神经网络比如GAN来指导图像压缩,而本文认为图像对应的文本模态可以为辅助图像压缩提供额外高级图像语义信息,该多模态方法在图像质量保真度可接受的情况下节省了更多比特率。但是由于GAN网络在训练初期辨别能力受限,且在对图像分块处理时没有合理考虑重叠部分的区域,导致收敛时间延长,压缩性能受影响。为此,我改进了分块策略并记录块重叠位置,同时采用基于大规模数据集预训练的深度网络作为判别器,经过微调后与模型共同训练,并在数据集上验证了改进对图像压缩性能的提升。
-

WACV 2023 | Relation Preserving Triplet Mining for Stabilising the Triplet Loss in Re-identification Systems
在车辆重识别任务中,我们面临着类内间距大、类间间距小的挑战。以往,人们通常采用难样本挖掘三元组方法来解决这个问题。然而这种方法却让网络在正样本学习过程中感到困惑,导致网络无法很好地泛化。为此,本文采用了传统特征点匹配算法GMS来测量图像之间的匹配值,并选择中等匹配值作为正样本,以提升网络性能。但是不论是难样本还是中等匹配样本,都可能导致网络过于关注某一类别。为解决该问题,我设计了一个渐进式训练过程,从简到难,以确保充分利用所有样本并增强网络的泛化能力。
-
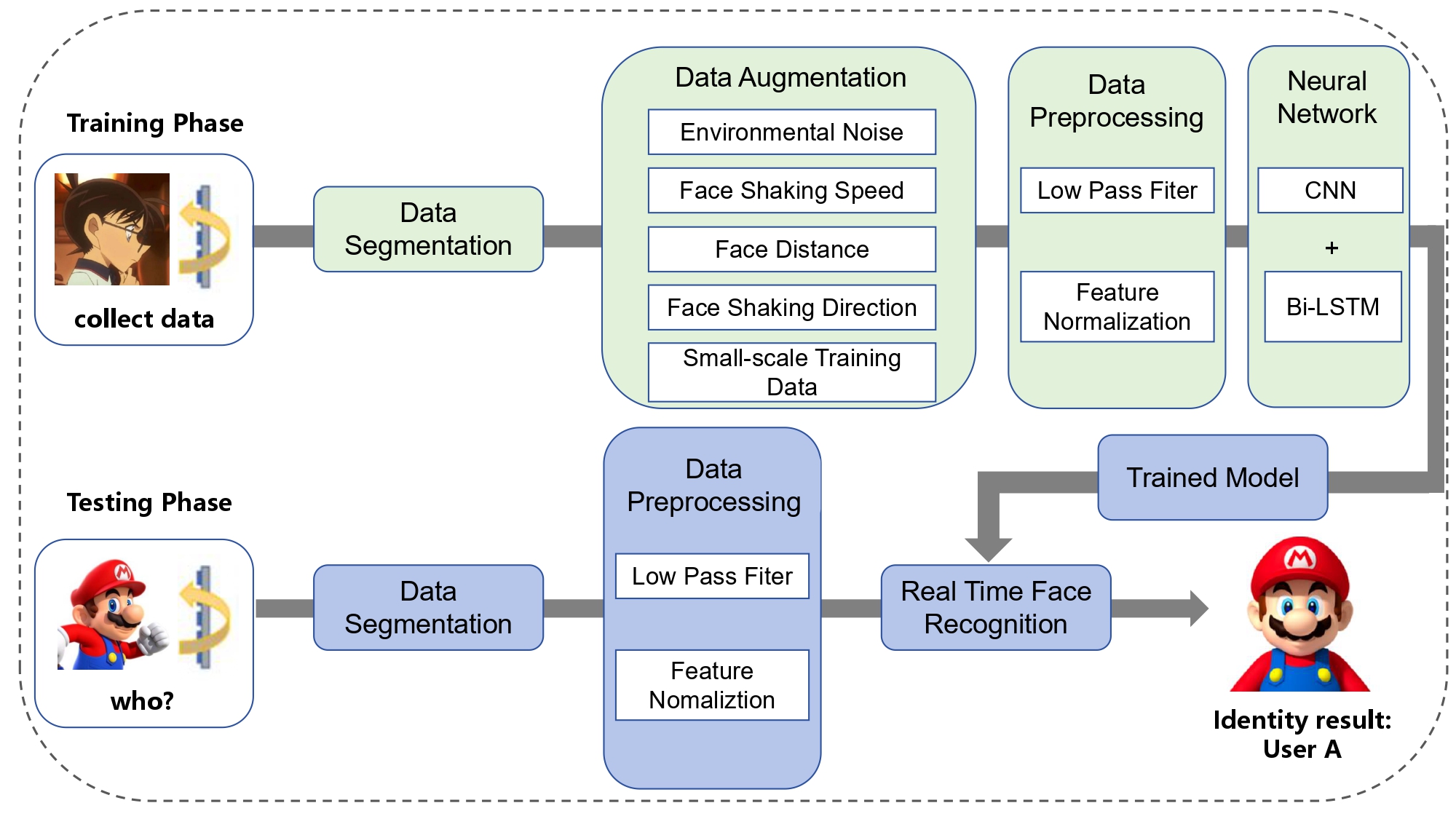
UbiComp 2021 | RFaceID: Towards RFID-based Facial Recognition
人脸识别技术近年来在多个领域内得到了广泛的普及和应用。然而,传统的基于视觉的人脸识别方法存在一定的局限性,如在光照不足或强光条件下识别准确率低,存在隐私泄露风险等。为避免上述问题所造成的识别影响,本文提出了一个基于RFID的人脸识别新系统。由于每个人有着独特的面部特征,在RFID标签矩阵前会产生不同的多路径反射,进而产生可区分的特征参数RSS和phase值。我根据文章收集的100个人的面部摇动参数,复现了原文的数据增强技术以增强训练数据的多样性,经过数据预处理,最后使用深度学习实现了高精度的人脸识别。实验中还探究了识别距离,用户外观变化和主被动攻击等因素对系统识别效果的影响。
-
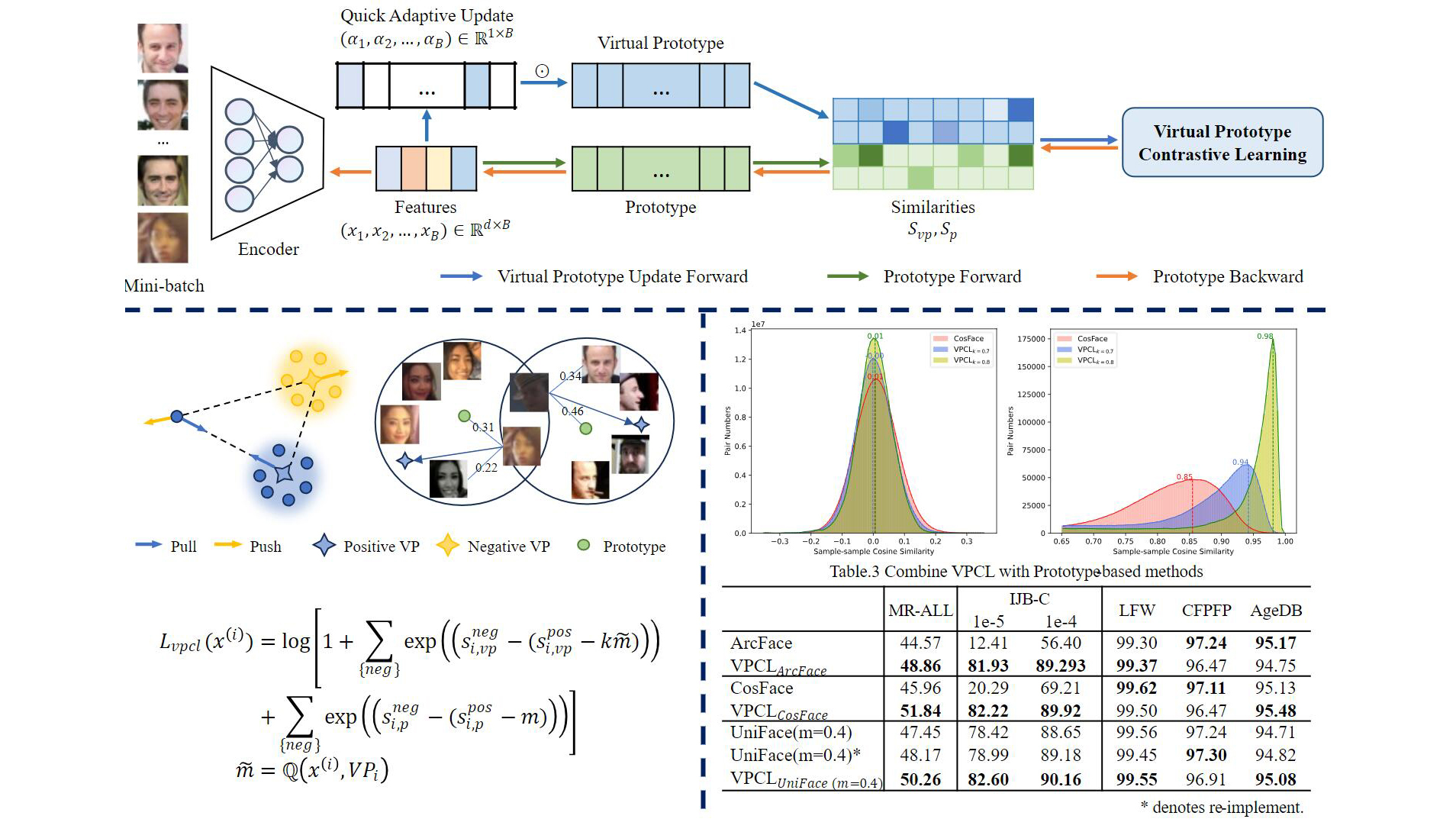
ICCV 2023 | UniFace: Unified Cross-Entropy Loss for Deep Face Recognition
统一阈值在人脸识别中起着至关重要的作用。现存的算法忽略了人脸识别的公平性。UniFace从一个统一阈值出发,推导出统一交叉熵损失函数(UCE Loss),其中统一的b,是性能提升的关键。针对Softmax只关注于寻找一个决策边界来分离不同原型,而没有考虑特征的类内紧致性。我们进一步提出了虚拟原型用于促进样本间内聚性,同时避免了复杂难样本挖掘。我们提出了一种统一的损失函数形式: 虚拟原型对比学习(VPCL),可以允许虚拟原型轻松嵌入到表征学习框架当中,并且持续提供改进性能。我们在大量的流行数据集上验证了虚拟原型的优越性。
-

TMI 2023 | Multi-Level Global Context Cross Consistency Model for Semi-Supervised Ultrasound Image Segmentation with Diffusion Model
医学图像分割是计算机辅助诊断的关键步骤,而卷积神经网络是当今流行的分割网络。 然而,固有的局部操作特性使得难以关注不同位置、形状和大小的病灶的全局上下文信息。 半监督学习可用于从标记和未标记样本中学习,减轻手动标记的负担。 然而,在医疗场景中获取大量未标记图像仍然具有挑战性。 为了解决这些问题,我们提出了一种多级全局上下文交叉一致性(MGCC)框架,该框架使用潜在扩散模型(LDM)生成的图像作为半监督学习的未标记图像。 这框架涉及两个阶段。 在第一阶段,LDM用于生成合成医学图像,这减少了数据注释的工作量并解决了与收集医学数据相关的隐私问题。 在第二阶段,将不同级别的全局上下文噪声扰动添加到辅助解码器的输入,并保持解码器之间的输出一致性以提高表示能力。
-
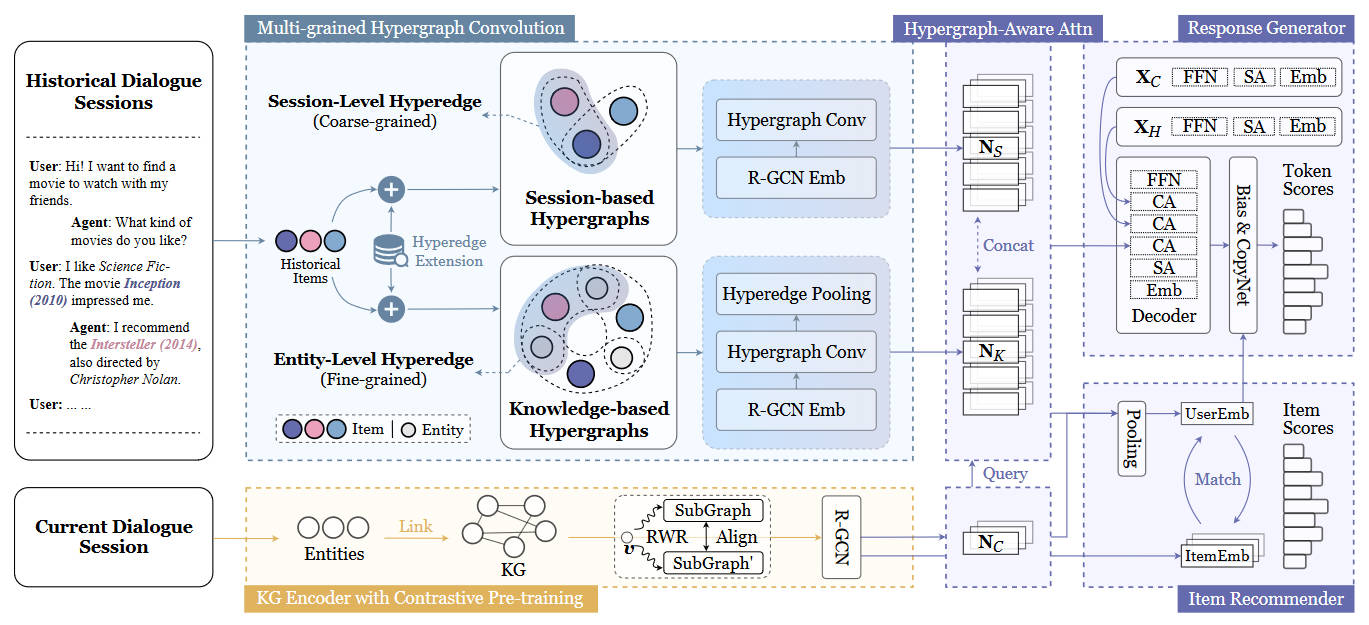
AI Open 2023 | Multi-grained Hypergraph Interest Modeling for Conversational Recommendation
为了解决传统对话推荐系统(CRS)中的数据稀缺性问题,MHIM这篇论文使用超图来建模用户的历史会话以形成基于会话的超图,并使用外部知识图并构建一个基于知识的超图,从不同粒度上捕捉用户偏好,然后在这两种超图上进行多粒度超图卷积,并利用对比子图预训练来开发具有兴趣感知的CRS。本次复现工作在其基础上进一步做出两方面的改进:1)为了进一步缓解数据稀缺性,引入外部数据集进行数据增强;2)改变超边扩展的条件,实验结果表明两种措施均在一定程度上带来了性能的提高。
-
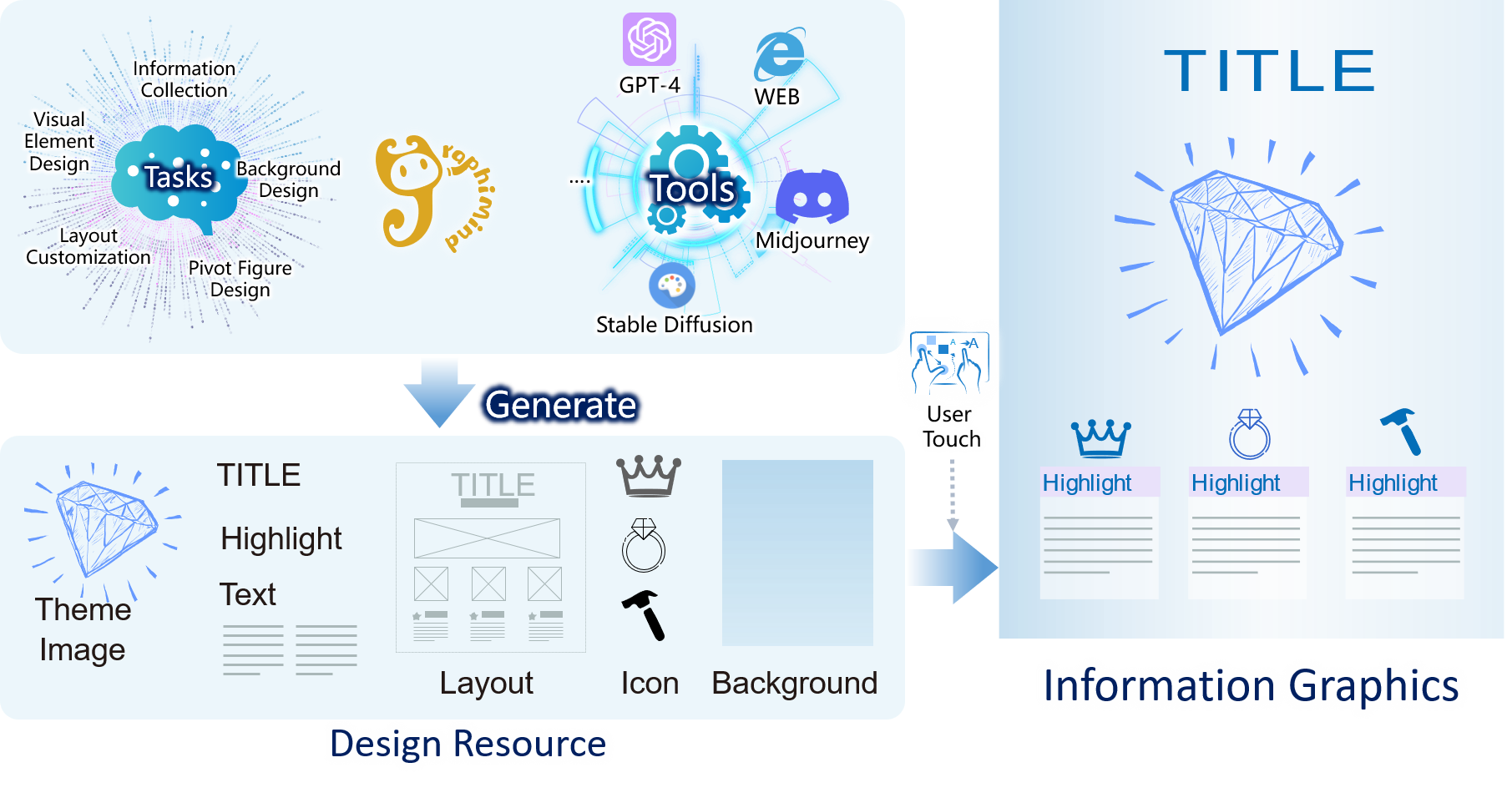
Submitted | GraphiMind: LLM-centric Interface for Information Graphics Design
信息图设计面临着专业门槛高、耗时较长以及频繁切换各类工具等难题。针对这些问题,本课题提出了一个以大语言模型为核心的交互式界面 GraphiMind,旨在减轻新手用户的设计压力。GraphiMind由两大部分构成:自然语言对话界面和图形编辑界面。用户可通过对话界面与大语言模型Agent进行交流,表达其设计意图。Agent能够智能地识别出相关的设计任务,并调用相应的设计工具得到设计资源。这些设计资源随后会自动集成到图形编辑界面的画板上,用户可以通过点击和拖拽的方式,对它们进行更为精细的调整。用户实验表明,与PowerPoint软件相比,GraphiMind让信息图的设计过程更加流畅且节省时间。
-

NeurIPS 2022 | Model-Based Imitation Learning for Urban Driving
人类是根据有限的感官来感受并理解世界,我们做出的决策大多情况下都依赖于我们的“世界模型”。当我们看到蜻蜓低飞时,我们或许会想到即将要下雨。基于该思想,该论文提出了一种基于模型的模仿学习方法,用于共同学习世界模型和自主驾驶的策略。该论文利用三维几何作为归纳偏置,直接从专家演示的高分辨率视频中学习高度紧凑的潜在空间。该模型可以预测各种合理的状态和行动,这些状态和行动可以被解释为鸟瞰式的语义分割。此外,它可以根据完全在想象中预测的计划执行复杂的驾驶动作。 但是该论文使用模仿学习来模仿人类专家数据可能会使智能体在某些场景下表现不好。为此,我引入了具有特权模式的强化学习教练来提升其性能,它可以利用多种传感器信息来感知环境并输出结果。实验结果表明其在一定程度上有性能提升。
 address
address
 Tel & FAX
Tel & FAX
 E-mail
E-mail



 address
address
 Tel & FAX
Tel & FAX
 E-mail
E-mail

