开yun体育官网入口登录苹果
College of Computer Science and Software Engineering, SZU

Cross-view Geo-localization with Layer-to-Layer Transformer
Conference on Neural Information Processing Systems (NeurIPS)
Hongji Yang Xiufan Lu Yingying Zhu∗
Shenzhen University
Abstract
In this work, we address the problem of cross-view geo-localization, which estimates the geospatial location of a street view image by matching it with a database of geo-tagged aerial images. The cross-view matching task is extremely challenging due to drastic appearance and geometry differences across views. Unlike existing methods that predominantly fall back on CNN, here we devise a novel layer-to-layer Transformer (L2LTR) that utilizes the properties of self-attention in Transformer to model global dependencies, thus significantly decreasing visual ambiguities in cross-view geo-localization. We also exploit the positional encoding of the Transformer to help the L2LTR understand and correspond geometric configurations between ground and aerial images. Compared to state-of-the-art methods that impose strong assumptions on geometry knowledge, the L2LTR flexibly learns the positional embeddings through the training objective. It hence becomes more practical in many real-world scenarios. Although Transformer is well suited to our task, its vanilla self-attention mechanism independently interacts within image patches in each layer, which overlooks correlations between layers. Instead, this paper proposes a simple yet effective self-cross attention mechanism to improve the quality of learned representations. Self-cross attention models global dependencies between adjacent layers and creates short paths for effective information flow. As a result, the proposed self-cross attention leads to more stable training, improves the generalization ability, and prevents the learned intermediate features from being overly similar. Extensive experiments demonstrate that our L2LTR performs favorably against state-of-the-art methods on standard, fine-grained, and cross-dataset cross-view geo-localization tasks. The code is available online.

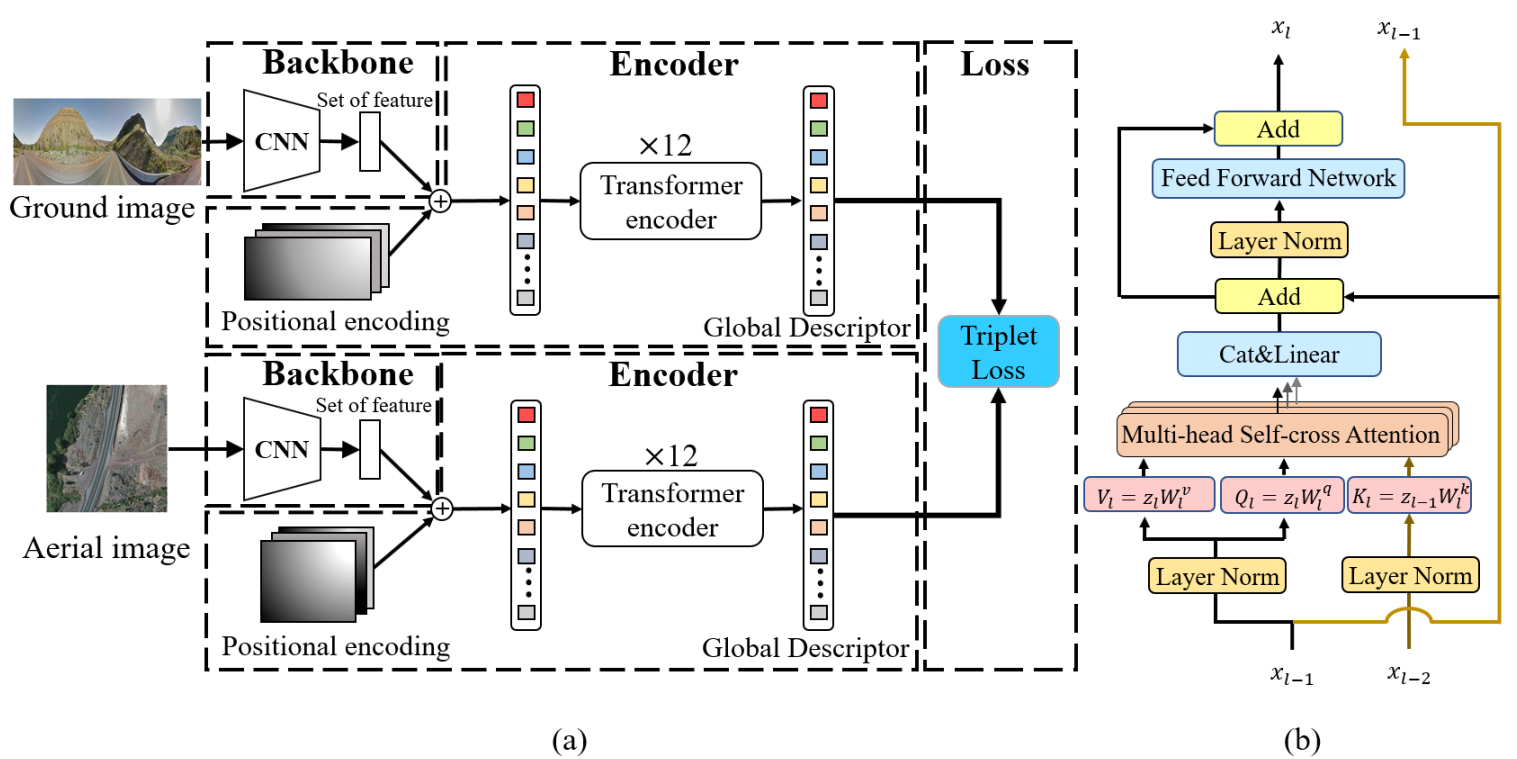
Figure 1: (a) Overview of our layer-to-layer Transformer (L2LTR). (b) Illustration of the encoder layer with self-cross attention in the L2LTR. ![]() denotes the input of layer
denotes the input of layer ![]() .
.
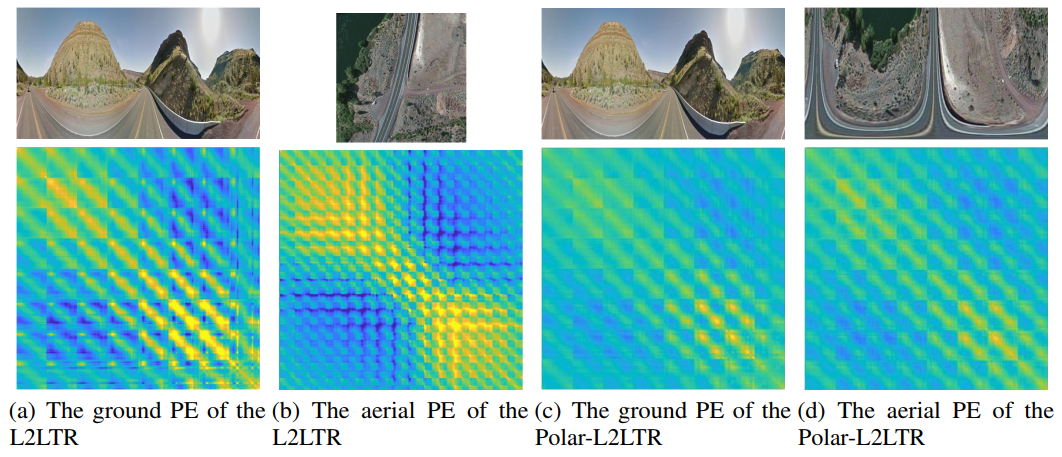
Figure 3: Cosine similarity between the learnable positional embeddings (PE). Yellow indicates the two positional embeddings are closer. Better viewed in color and with zoom-in.
Acknowledgement
This work was supported by: (i) National Natural Science Foundation of China (Grant No. 62072318);(ii) Natural Science Foundation of Guangdong Province of China (Grant No. 2021A1515012014);(iii) Fundamental Research Project in the Science and Technology Plan of Shenzhen (Grant No.JCYJ20190808172007500).
Bibtex
@inproceedings{YangWZ22,
author = {Zhanyuan Yang and Jinghua Wang and Yingying Zhu},
title = {Few-Shot Classification with Contrastive Learning},
booktitle = {Computer Vision - {ECCV} 2022 - 17th European Conference, Tel Aviv,Israel, October 23-27, 2022, Proceedings, Part {XX}},
pages = {293--309},
year = {2022},
url = {https://doi.org/10.1007/978-3-031-20044-1\_17},
doi = {10.1007/978-3-031-20044-1\_17},
} @inproceedings{DBLP:conf/nips/YangLZ21,
author = {Hongji Yang and Xiufan Lu and Yingying Zhu},
title = {Cross-view Geo-localization with Layer-to-Layer Transformer},
booktitle = {Advances in Neural Information Processing Systems 34: Annual Conference on Neural Information Processing Systems 2021, NeurIPS 2021, December 6-14, 2021, virtual},
pages = {29009--29020},
year = {2021},
url={https://proceedings.neurips.cc/paper/2021/hash/f31b20466ae89669f9741e047487eb37-Abstract.html},
}
Downloads





