开yun体育官网入口登录苹果
College of Computer Science and Software Engineering, SZU

IEEE TRANSACTIONS ON GEOSCIENCE AND REMOTE SENSING (IEEE T GEOSCI REMOTE)
Xiufan Lu Siqi Luo Yingying Zhu*
Shenzhen University
Abstract
Cross-view image geo-localization is a challenging task of estimating the geospatial location of a street-view image by matching it with a database of geotagged aerial/satellite images, and vice versa. Compared to existing CNN-based approaches that attempt to generate discriminative representations in a single step for this task, in this article, we instead advocate endowing the network with the capability of progressive self-correcting. Toward this target, we propose a novel step-adaptive iterative refinement network (SIRNet), which decomposes the complex learning process into several refinement steps while adapting the refinement steps specifically for each input. Specifically, the SIRNet takes the output of the backbone as a rough network prediction and iteratively refines it via an iterative refinement module (IRM). The IRM cascades several refinement blocks sharing the same structure for progressive self-correcting. For each refinement block, the goal is to improve the output of the previous refinement block under the guidance of heightwise context. In this way, the IRM is capable of improving the rough network prediction step by step, and the refined features are increasingly focused on more discriminative scene regions as they are iteratively refined. In addition, considering different characteristics of input images, we devise an adaptive step estimation (ASE) mechanism, which enables our SIRNet to adapt the number of refinement steps to each input automatically. Concretely, the ASE is performed by comparing features at adjacent refinement steps, estimating whether the next step brings improvements, and finally making a halting decision at each refinement step. With the ASE, our SIRNet becomes a dynamic architecture that considers different characteristics of the inputs when performing the iterative refinement. Extensive experiments demonstrate that our SIRNet performs favorably against the state-of-the-art methods on the CVUSA and the CVACT datasets. Furthermore, quantitative and qualitative experimental results demonstrate our approach’s wide applicability, impressive generalization ability, and robustness.

Fig. 2. Visualization of generated feature maps on the CVUSA dataset [4] comparing our proposed SIRNet with two state-of-the-art models, i.e., SAFA [5]and DSM [6]. For a fair comparison, we warp aerial images using polar transform as in [5] and [6], a simple trick that geometrically aligns ground and aerialimages. “GT” is short for ground truth. We indicate regions with higher activation values in yellow, and for ease of reference, we box the discriminative scene regions in green

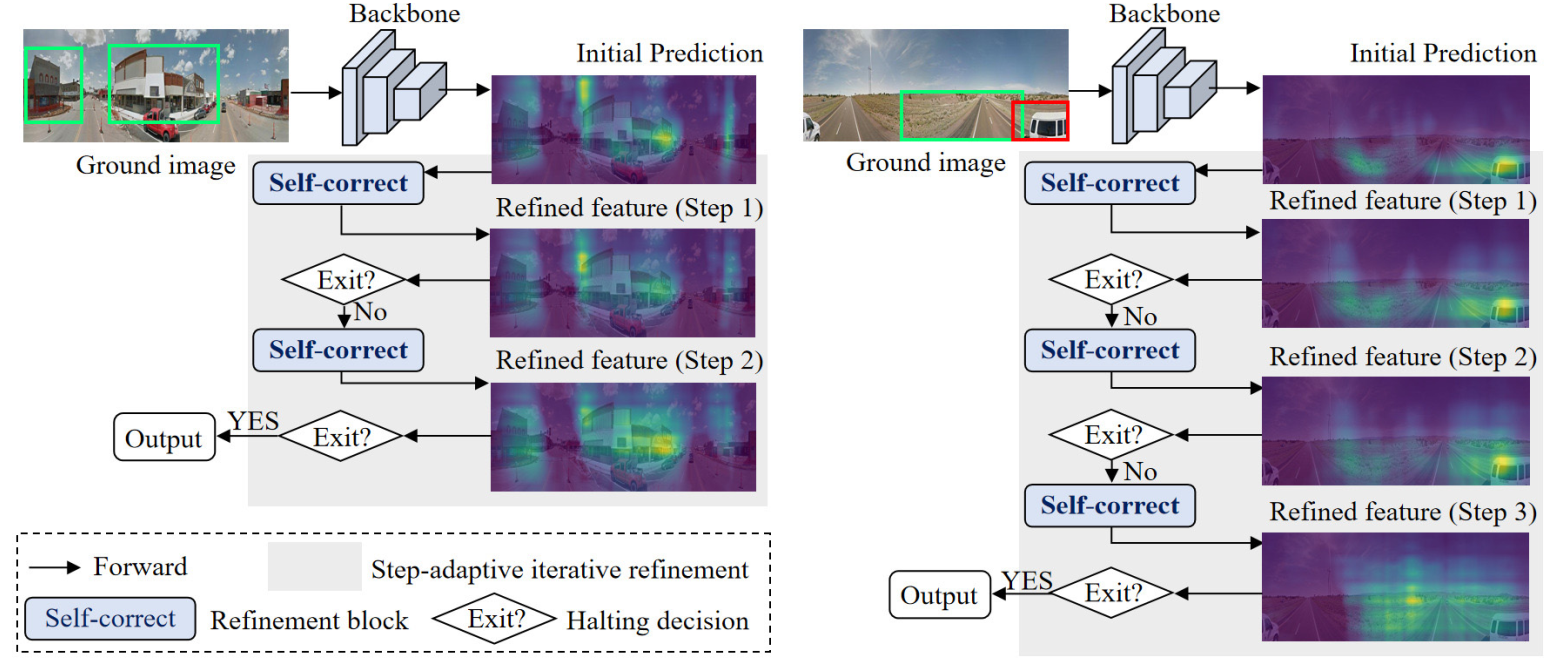
Fig. 3. Our proposed SIRNet iteratively refines the rough predictions output from the backbone with refinement steps conditioned on each input. (Left) Two-step iterative refinement process. (Right) Three-step iterative refinement process. The visualization examples demonstrate that the SIRNet is capable of highlighting discriminative regions (left and right) while suppressing transient occlusions (right) step by step. For ease of reference, we box discriminative regions and transient occlusions in green and red, respectively.

Fig. 4. Overview of our SIRNet, which consists of four components: the backbone networks, the IRMs (highlighted in green), the aggregation modules (gray triangle), and the ASE mechanisms (highlighted in purple). Specifically, the IRM contains T cascaded refinement blocks to improve the rough predictions output from the backbone step by step, and the structure of a single refinement block at step T is depicted on the right. The ASE, which is used solely at inference, enables the network to automatically adapt the number of refinement steps to each input query by making halting decision at each refinement step.
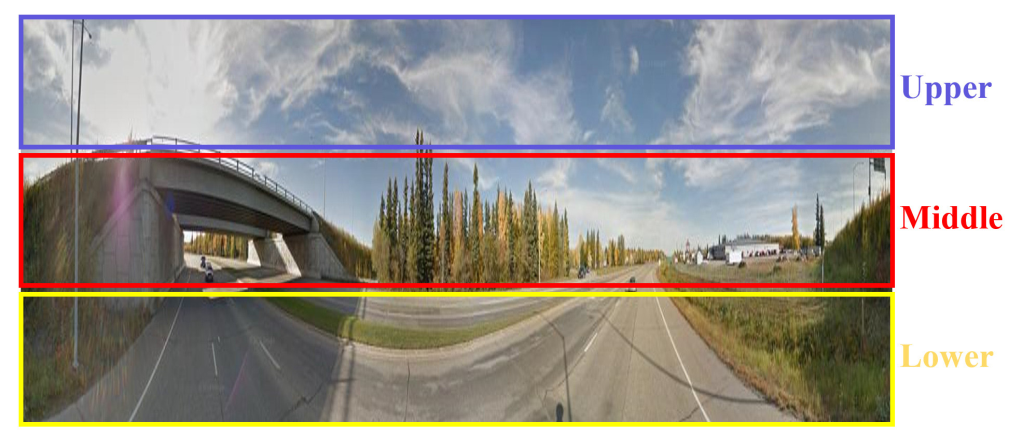
Fig. 5. Each part of an image divided into three horizontal sections has a significantly different object distribution from each other. For example, roads lie mainly in the lower region.
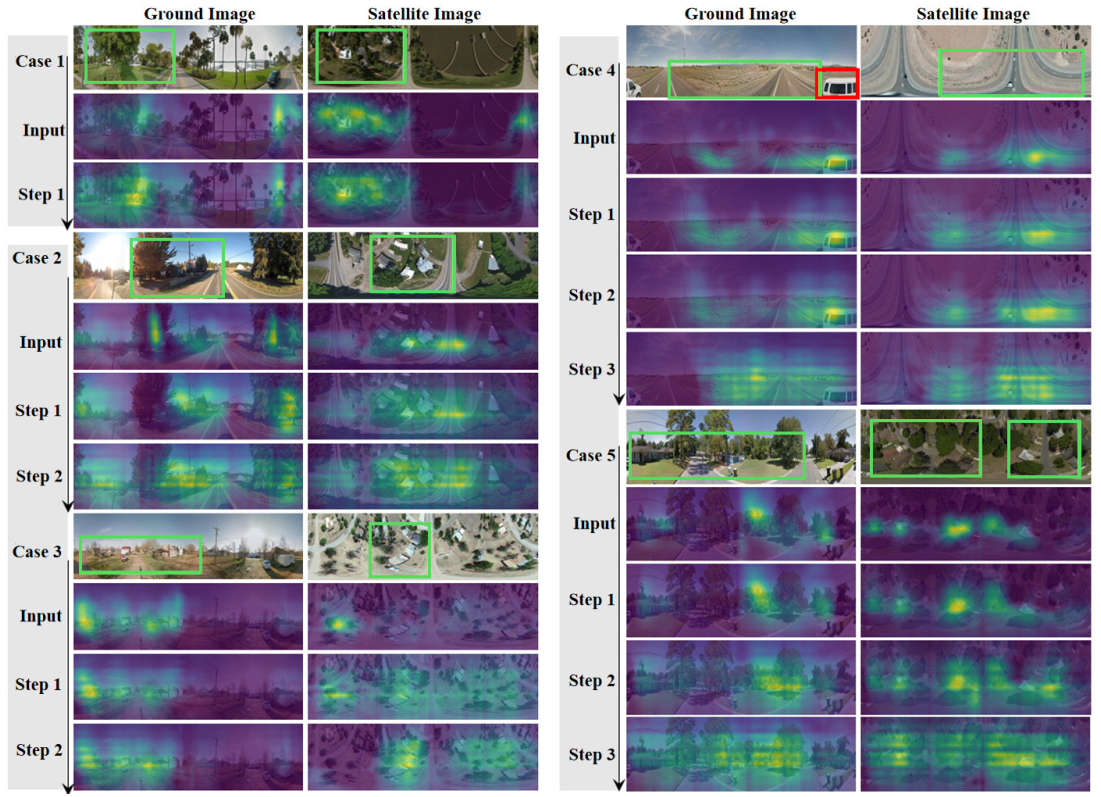
Fig. 12. Visualization of the generated features of the SIRNet on CVUSA [4] to verify the progressive self-correcting capability of the SIRNet. First, we visualize the rough network prediction (denoted as “Input”) and the refined features of the IRM (denoted as “Step 1/2/3”). Second, we show that with the ASE, the SIRNet is capable of configuring the different number of refinement steps for each input sample (for cases 1, 2, and 3 and 4 and 5, the refinement steps are automatically set to 1, 2, and 3, respectively). Regions with higher activation values are indicated in yellow. For ease of reference, we box the discriminative regions and transient occlusions in green and red, respectively.
Acknowledgement
This work was supported in part by the National Natural Science Foundation of China under Grant 62072318, in part by the Natural Science Foundation of Guangdong Province of China under Grant 2021A1515012014, in part by the Science and Technology R&D Funds of Shenzhen under Grant JCYJ20190808172007500 and Grant 20220810142553001, and in part by the China University Industry-Academia-Research Innovation Funds under Grant 2021LDA12014.
Bibtex
@article{DBLP:journals/tgrs/LuLZ22,
author = {Xiufan Lu and Siqi Luo and Yingying Zhu},
title = {It's Okay to Be Wrong: Cross-View Geo-Localization With Step-Adaptive
Iterative Refinement},
journal = {{IEEE} Trans. Geosci. Remote. Sens.},
volume = {60},
pages = {1--13},
year = {2022},
url = {https://doi.org/10.1109/TGRS.2022.3210195},
doi = {10.1109/TGRS.2022.3210195},
biburl = {https://dblp.org/rec/journals/tgrs/LuLZ22.bib},
bibsource = {dblp computer science bibliography, https://dblp.org}
}
Downloads





